My ICRA 2026 digest
ICRA 2026 happened in Vienna, June 1–5. As with my ICRA 2023 digest, this is a brain-dump of my notes, photos, and links collected throughout the week — lightly edited, so expect raw conference-note energy. If you want the bird’s-eye view of the proceedings instead, I also made an interactive topic map of all 3,028 papers.
Mucho texto: Table of contents
Day 1 · Workshops: S2S — From Sea to Space8
- Tobias Fischer (QUT) — from sea to space, literally
- Jungseok Hong (MIT) — underwater 3D reconstruction by interleaving multimodal SLAM and incremental Gaussian splatting
- Josh Mangelson (BYU FROSTLab) — towards robust multi-agent underwater localization and coastal semantic mapping
- Teresa Vidal-Calleja (UTS) — spatial perception in marine, orbital, and planetary domains
- Hanumant Singh (Northeastern) — NeuSLAM: dense visual SLAM on edge devices
- Annette Stahl (NTNU) — resilient perception for field robotics in harsh maritime environments
- Industry spotlight: EONSEA
- Hiro Ono (JPL, remote) — toward interplanetary foundation models
Day 2 · Keynotes: Milford, Bera, Wang4
Day 3 · Posters, Carlone, Barfoot, and how to talk to humans6
Day 4 · Robot learning, planning and foundation models6
Day 5 · Workshops: Robots Meet Prior Maps10
- Maurice Fallon (Oxford) — where's my glasses: identifying change in scene graphs over time
- Jen Jen Chung (UQ) — exploring interactions with object-level maps
- Abhinav Valada (Freiburg) — open-world autonomy: representations, mapping, interaction
- Luca Carlone (MIT) — from maps to memories: present and future of spatial AI
- David Hsu (NUS) — open scene graphs for open-world navigation
- José Luis Sánchez-López (Luxembourg) — tightly integrating semantic-relational priors into SLAM
- Huan Yin (Hunan University, online) — BIM as a prior semantic map
- Javier Civera (Zaragoza) — mapping inside the human body
- Floor notes and links
- MM-SpatialAI workshop
Posters9
Day 1. Workshops: S2S — From Sea to Space

I spent day 1 at the S2S: From Sea to Space workshop — perception for the domains where GPS doesn’t reach and everything is trying to corrode, freeze, or irradiate your robot. A great lineup of invited talks plus a poster session.
Tobias Fischer (QUT) — from sea to space, literally
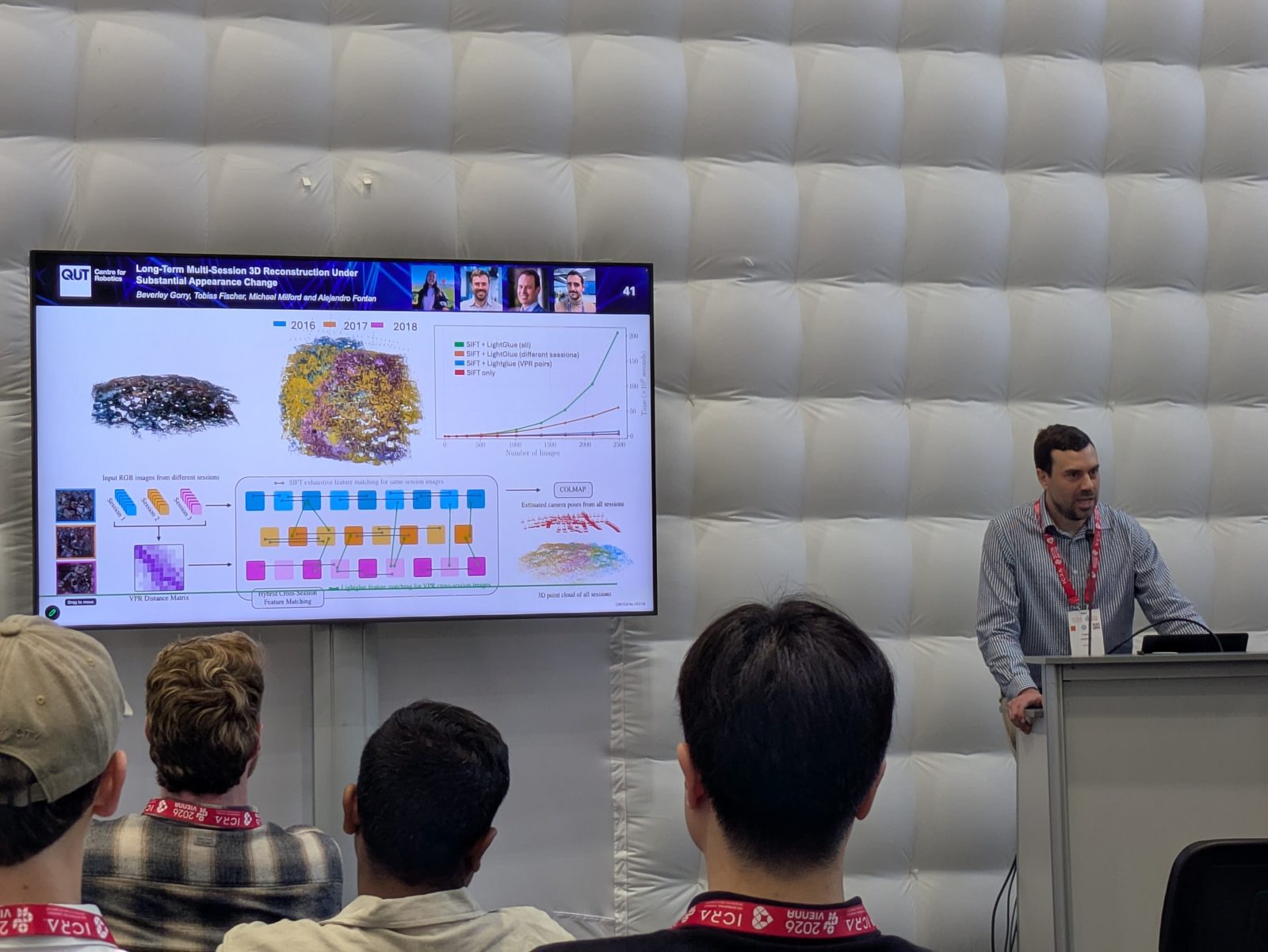
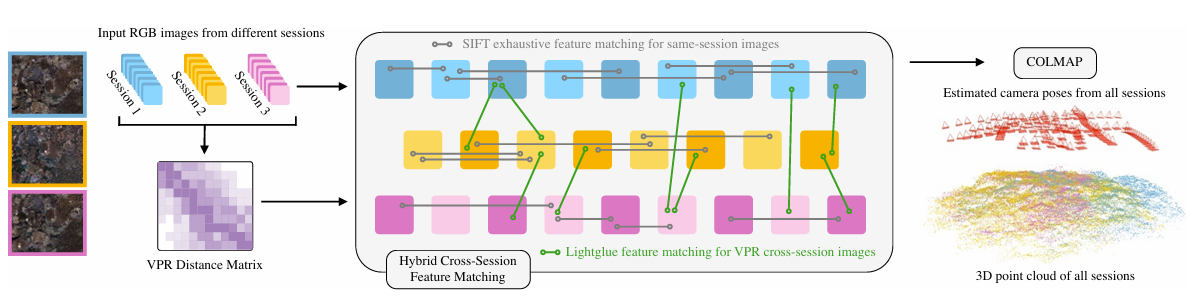
A tour through the QUT Centre for Robotics work spanning both ends of the workshop title:
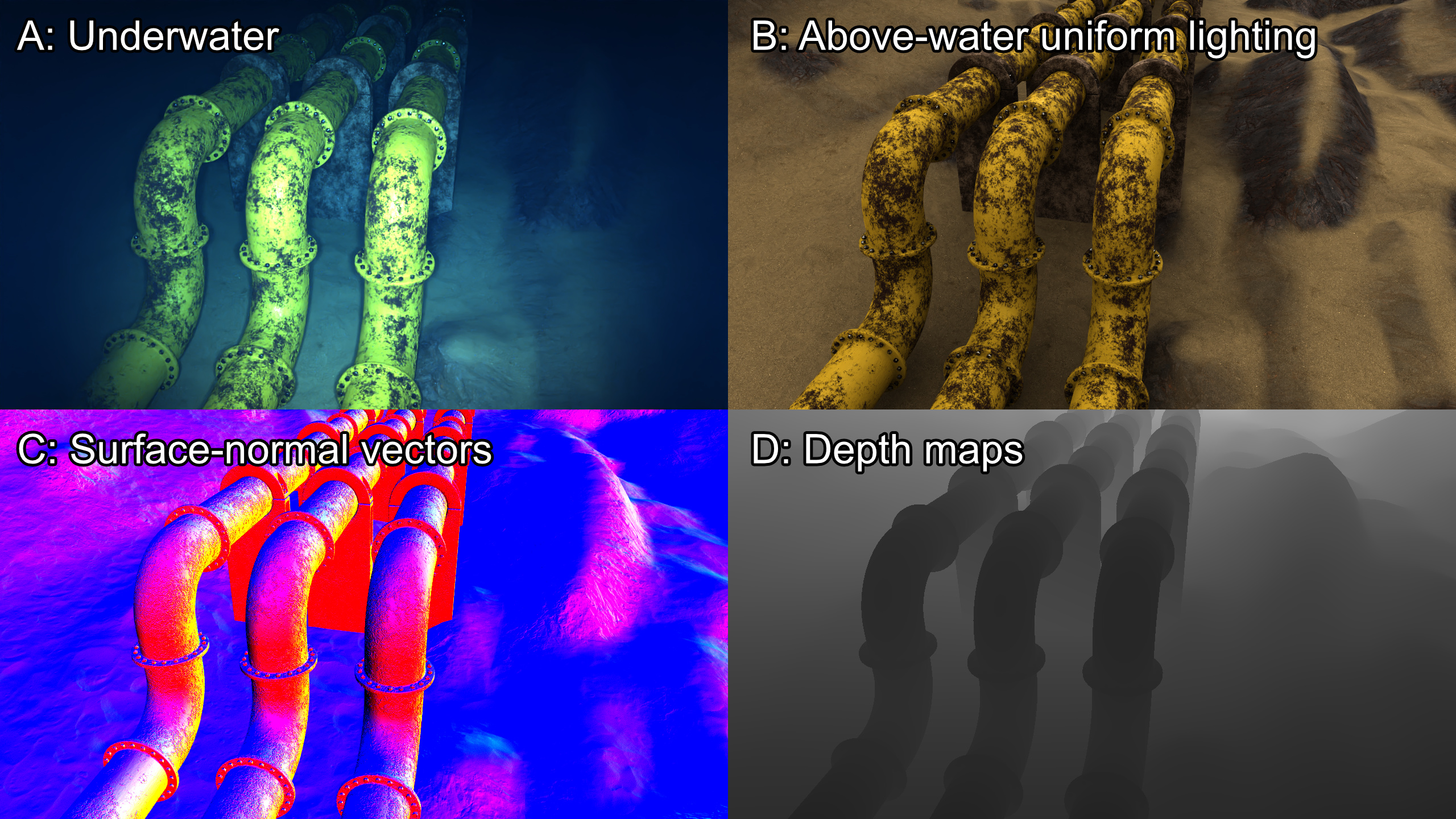
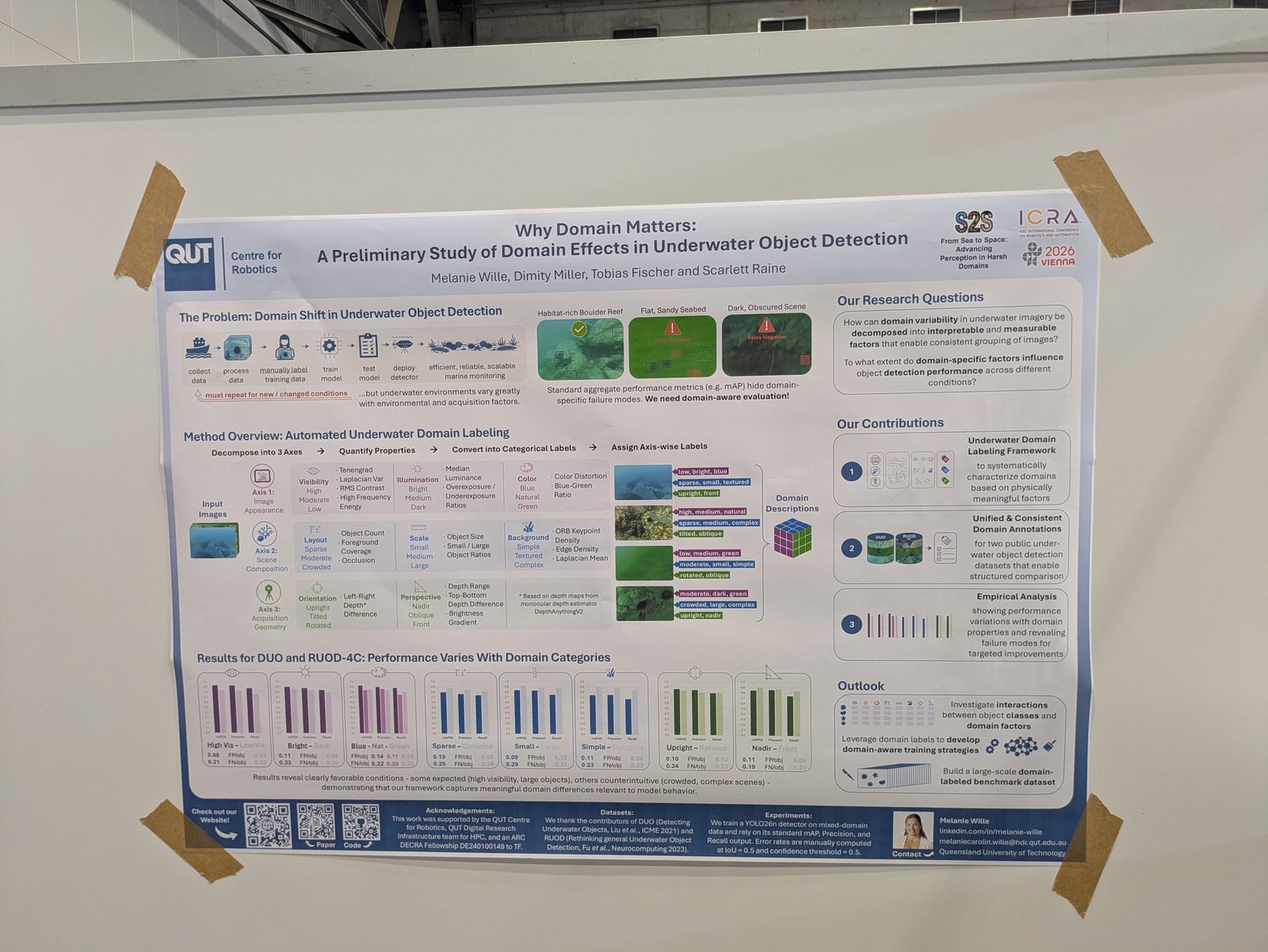
Why domain matters: a preliminary study of domain effects in underwater object detection
Underwater · Detection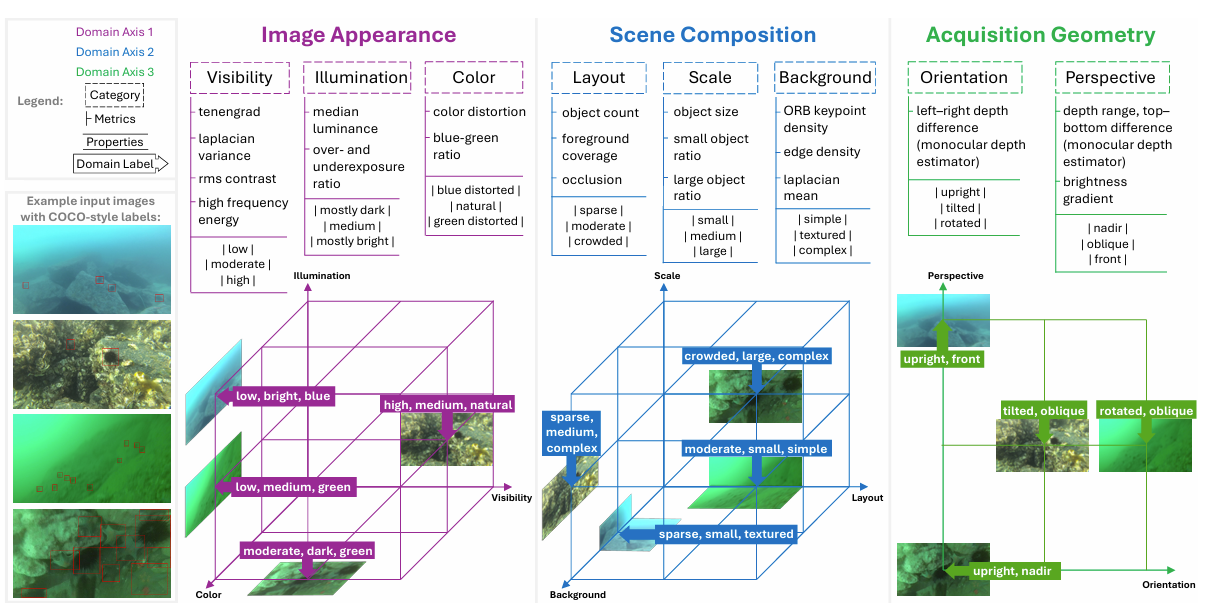
- Axis 1 — image appearance: visibility, illumination, color.
- Axis 2 — scene composition: scale, layout, background.
- Axis 3 — acquisition geometry: orientation, perspective.
Prepare for warp speed: sub-millisecond visual place recognition using event cameras
Event Cameras · VPR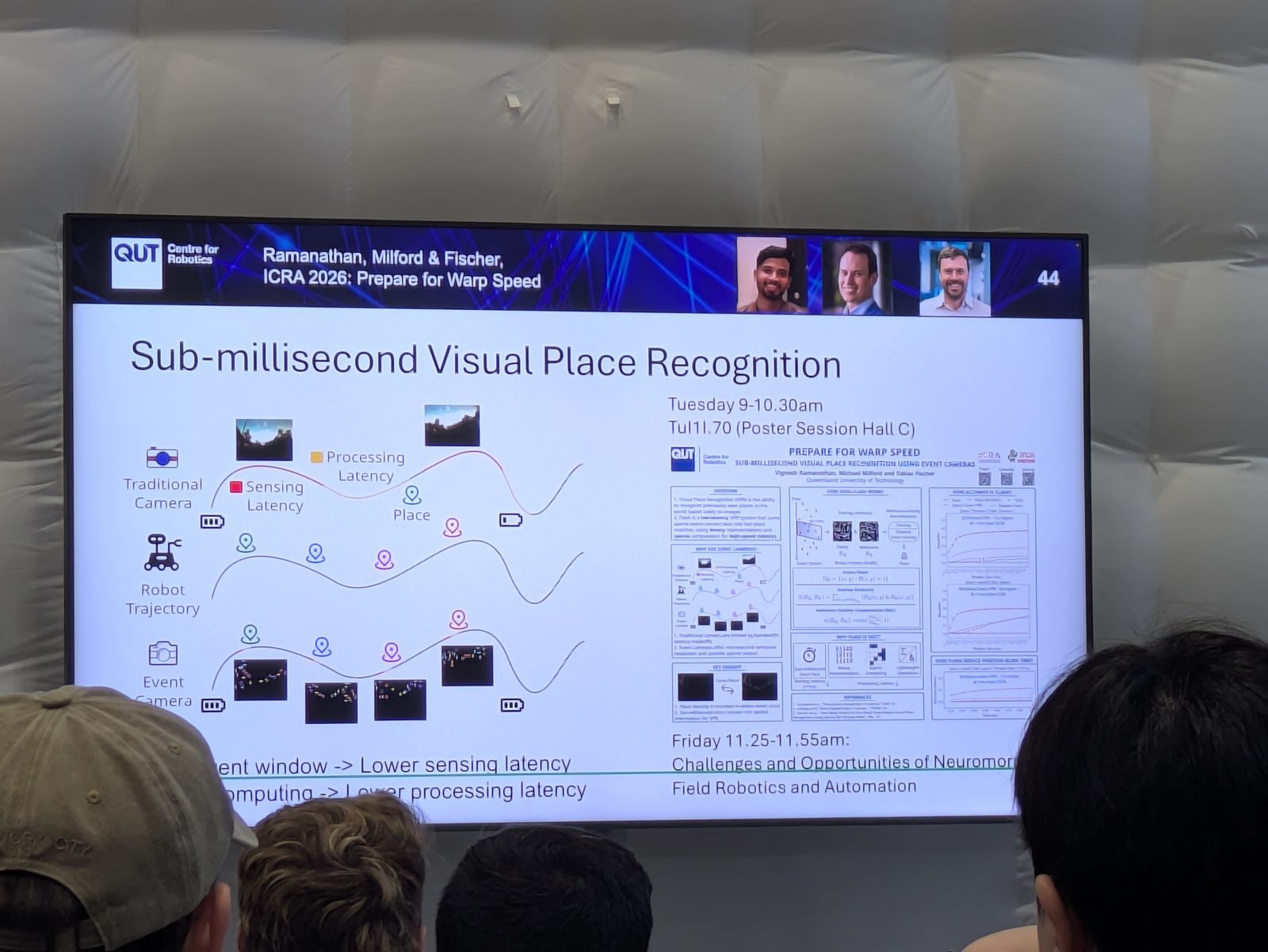
They also organize a marine robotics seminar series — once a month, international speakers, wide range of topics: sgraine.github.io/marine-robotics-seminars. Recordings available on YouTube too.
Jungseok Hong (MIT) — underwater 3D reconstruction by interleaving multimodal SLAM and incremental Gaussian splatting

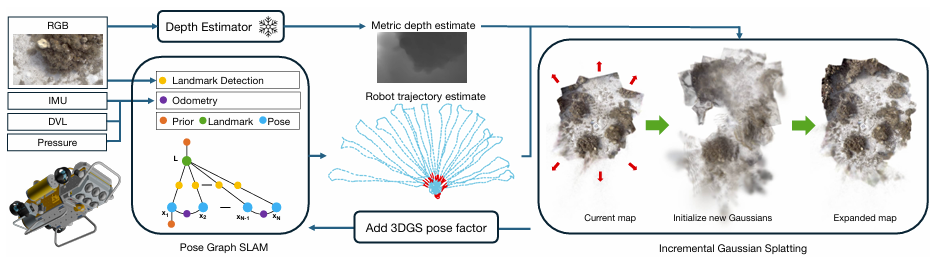
Josh Mangelson (BYU FROSTLab) — towards robust multi-agent underwater localization and coastal semantic mapping


FROSTLab also has a few papers in the main proceedings this year:
- Weighted group-k consistent set maximization for outlier rejection of azimuth-elevation measurements,
- Terra: hierarchical terrain-aware 3D scene graph for task-agnostic outdoor mapping, and
- DreamSea: photorealistic 3D underwater terrain generation by latent fractal diffusion models.
Teresa Vidal-Calleja (UTS) — spatial perception in marine, orbital, and planetary domains

They use continuous spatial maps represented with Gaussian processes + linear operators. The motivation list is compelling: they can be linearly operated, they can be physics-driven through the kernel, computationally costly but can be made sparse for efficiency, the hyperparameters have intuitive meaning, and they run on CPU or GPU. The work builds on two threads:
Gaussian process gradient maps (GPGM)
Mapping · GP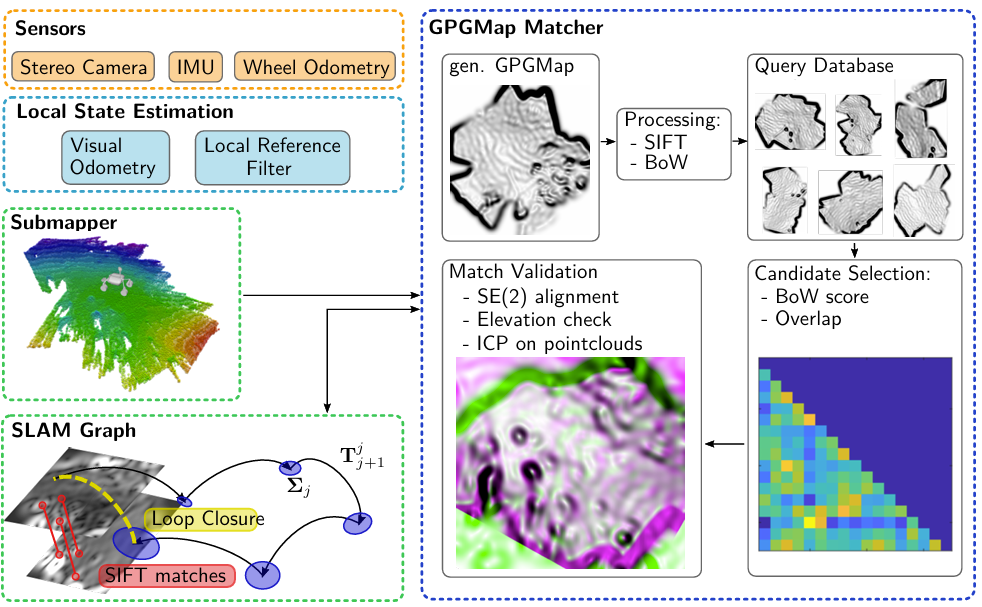

Hanumant Singh (Northeastern) — NeuSLAM: dense visual SLAM on edge devices

NeuSLAM: dense visual SLAM on edge devices
SLAM · Edge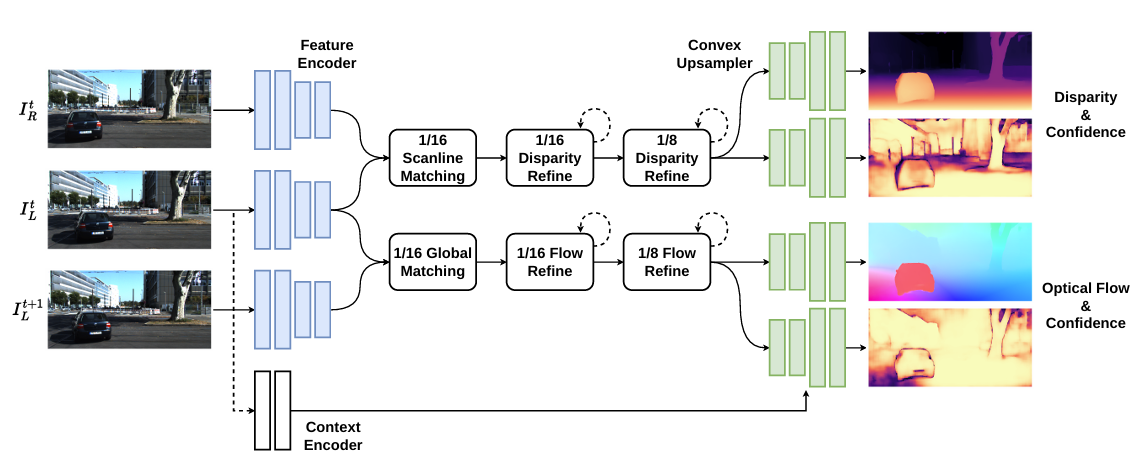
Annette Stahl (NTNU) — resilient perception for field robotics in harsh maritime environments

Among other things:

Heterogeneous multi-sensor tracking for an autonomous surface vehicle in a littoral environment
Dataset · Tracking
Industry spotlight: EONSEA

Hiro Ono (JPL, remote) — toward interplanetary foundation models

Can AI drive a Mars rover? — beamed in from JPL to close the day on the space end of the spectrum.
Day 2. Keynotes: Milford, Bera, Wang
Michael Milford — biology as engineering blueprint
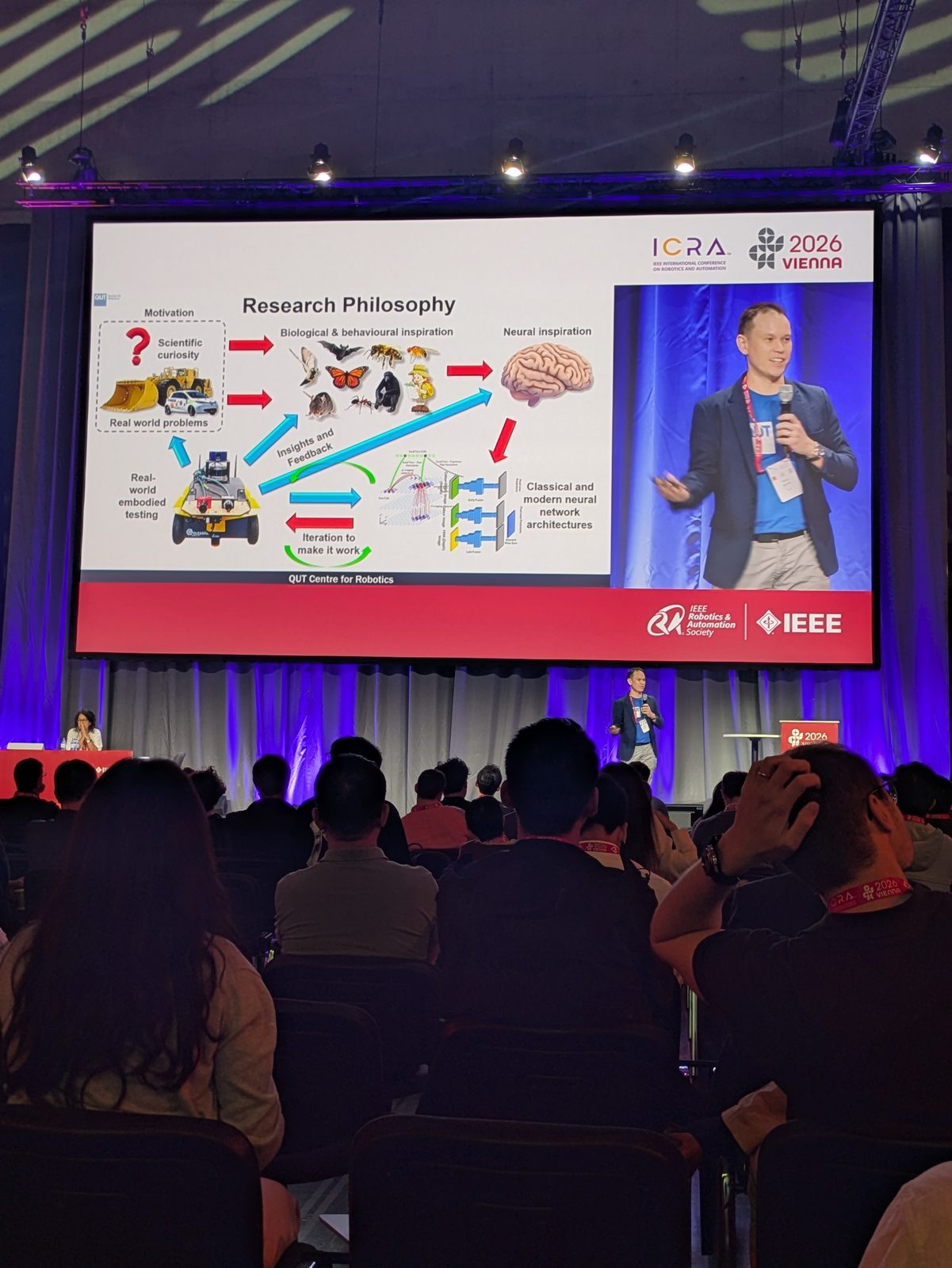

A very inspiring one. His research philosophy is to draw on three layers of inspiration for robotics — biological, behavioural, and neural — closing the loop from real-world embodied testing back to scientific curiosity. But he was also honest about why bio-inspired robotics is hard, and why it’s still a niche keyword compared to the hot topics of the day. The core problem: robot sensors aren’t the sensors living beings have — you can’t simply copy biology when both your hardware and our scientific understanding of the original fall short.
Twenty years of this thread, from RatSLAM to visual place recognition and neuromorphic sensors, all the way to a GPS-free positioning system:
RatSLAM: a hippocampus-inspired SLAM system
SLAM · Bio-inspired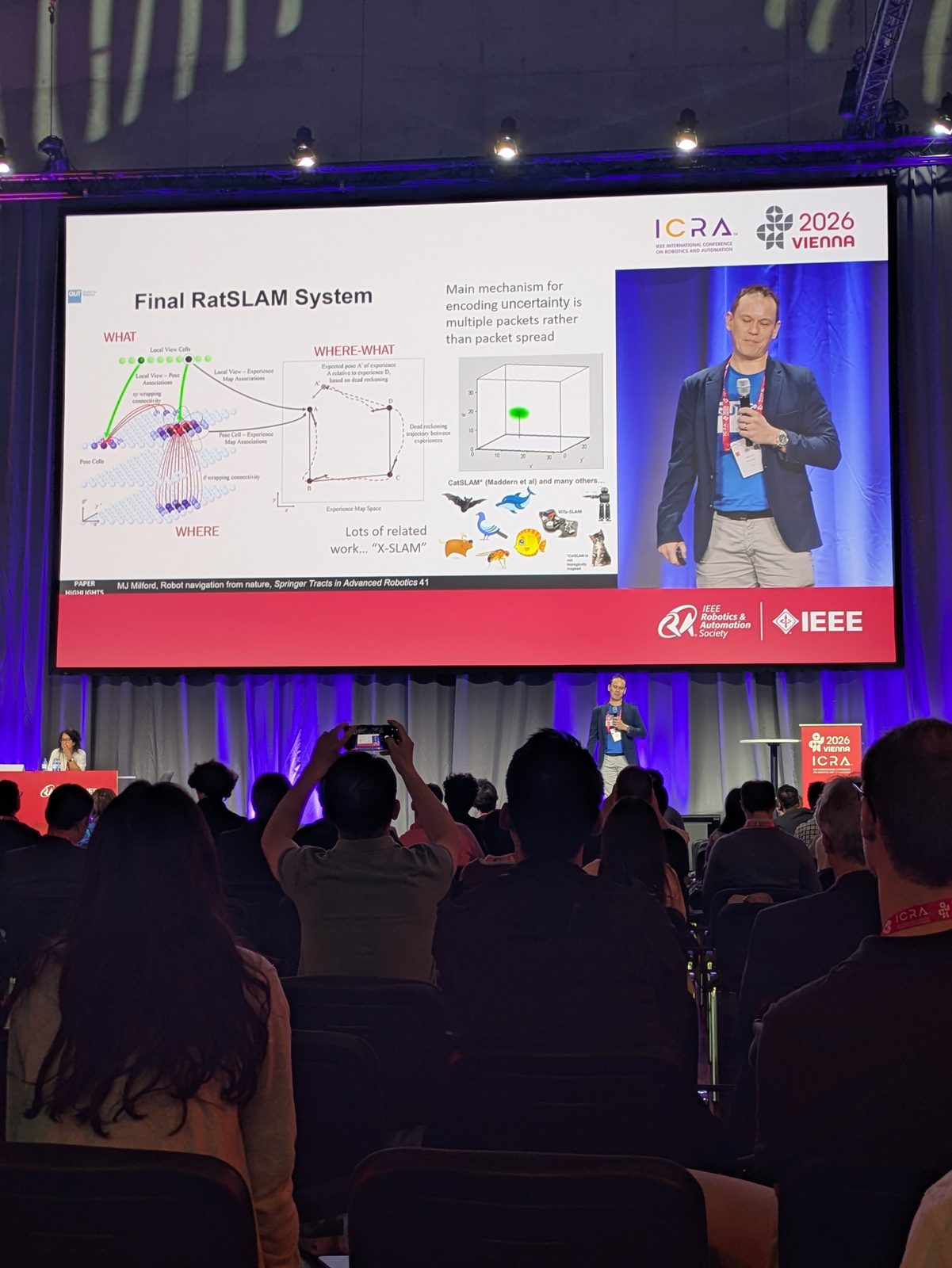

The Local Positioning System (LPS)
Positioning · GPS-free
Aniket Bera — safe navigation in unstructured, human-centered environments

“Learned models are very useful, but they should generate checkable outputs.”
Three take-home messages:
- Safety is not a module. It is the whole stack. Perception, prediction, planning, and control have to be coupled.
- Learning gives robots intuition; structure keeps them honest. Representations are powerful, but maps, logic, constraints, barriers, and solvers make them reliable.
- The real world does not give clean problem settings. Robots must operate in uncertain, cluttered, changing, and partially observable environments.
Two works from his lab that put this into practice:
FlashSLAM: accelerated RGB-D SLAM for real-time 3D scene reconstruction with Gaussian splatting
SLAM · 3DGS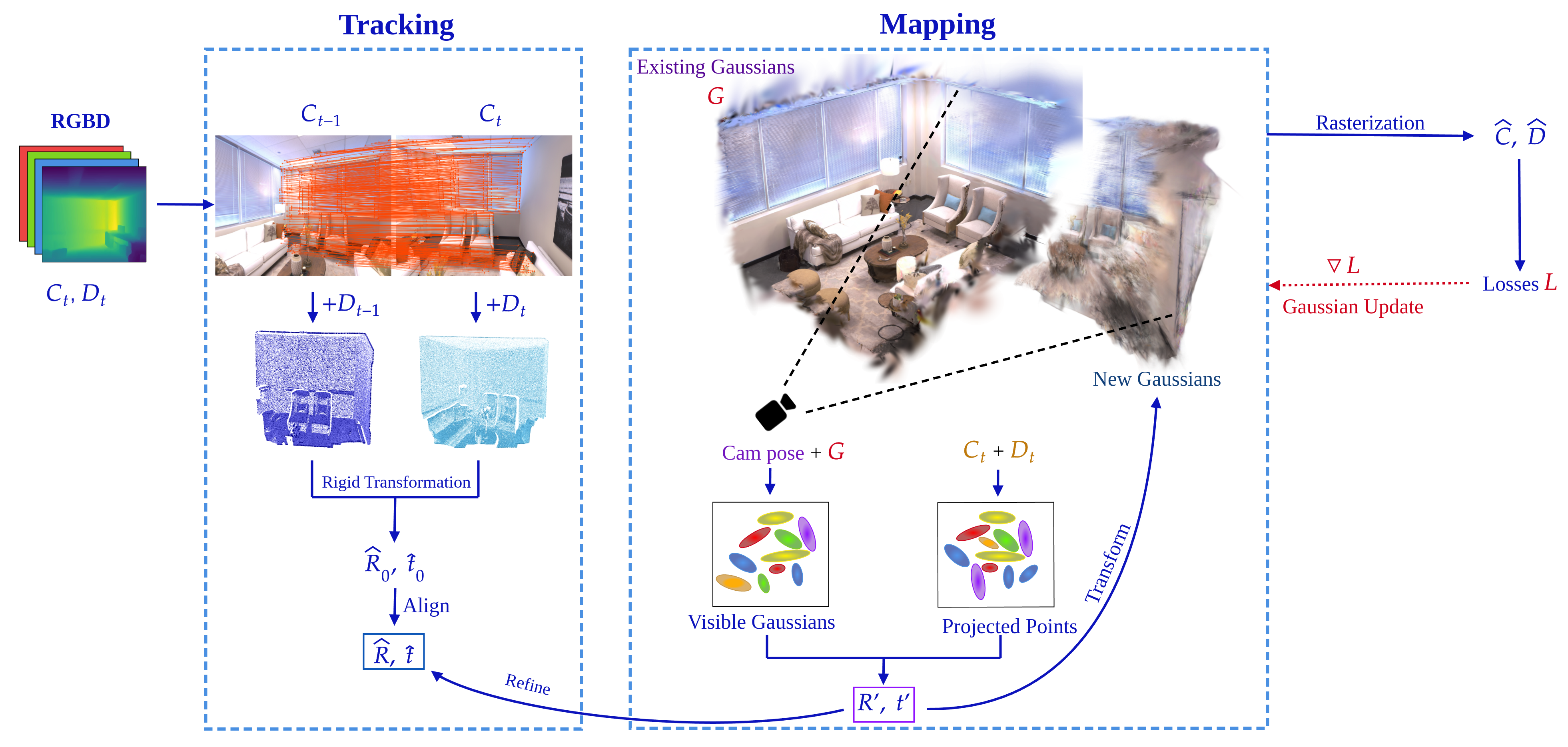
Tracking: (1) detect correspondence matches; (2) project matches to world coordinates using depth; (3) coarse-to-fine alignment — (a) initial pose from rigid transformation and point-cloud registration of the correspondences, (b) refinement via gradient-based optimization on rendering losses.
- Core idea: make pose a closed-form geometric registration problem, while keeping 3DGS optimization for map refinement.
- Prior bottleneck: rendering-based 3DGS-SLAM optimizes pose through a photometric loss. The gradients are expensive and can be ill-conditioned when overlap is sparse or depth is noisy.
- Their estimator: use learned correspondences from 2D-3D matches, back-project into point sets, solve SE(3) with Kabsch/SVD, then refine Gaussians and keyframes.
He framed FlashSLAM as the fast local map, then walked through the other world-modeling problems his lab solved around it — after the local map is fast, the remaining question is how to make it actionable: grounded, globally anchored, and logically usable.
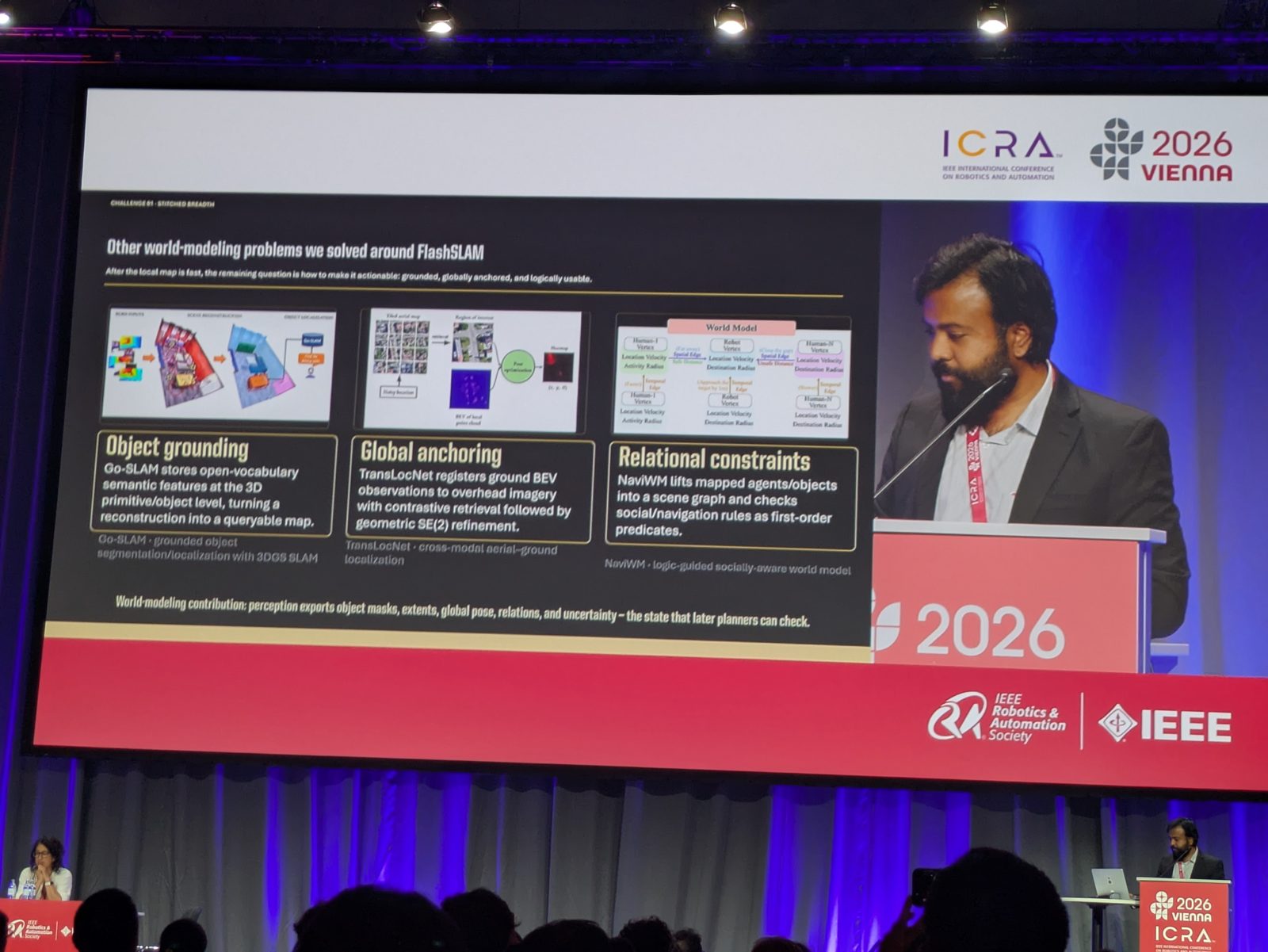
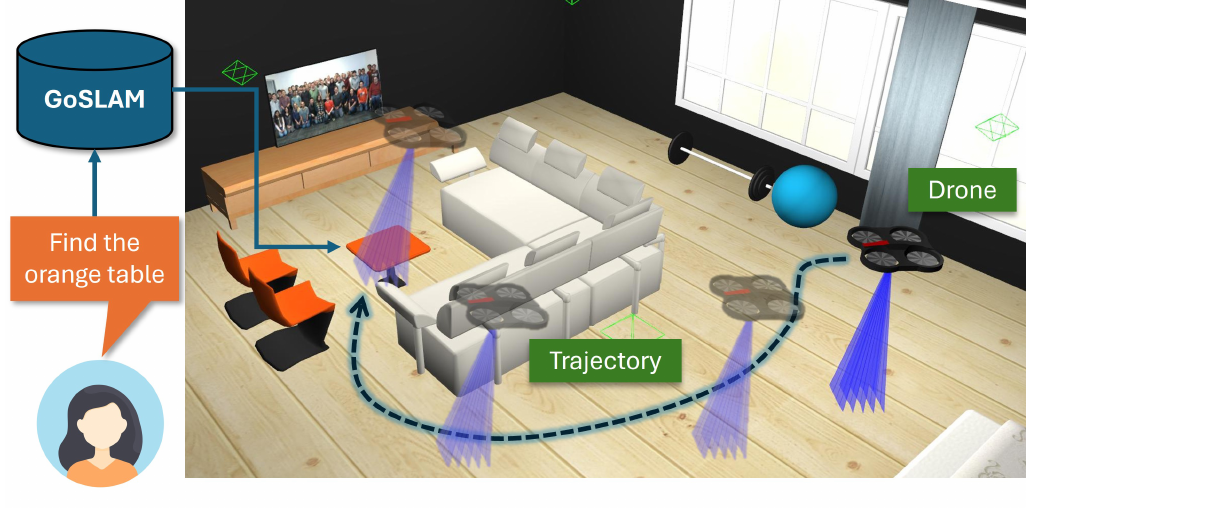
Global anchoring — TransLocNet
Cross-modal · LocalizationRelational constraints — NaviWM
Scene Graph · Logic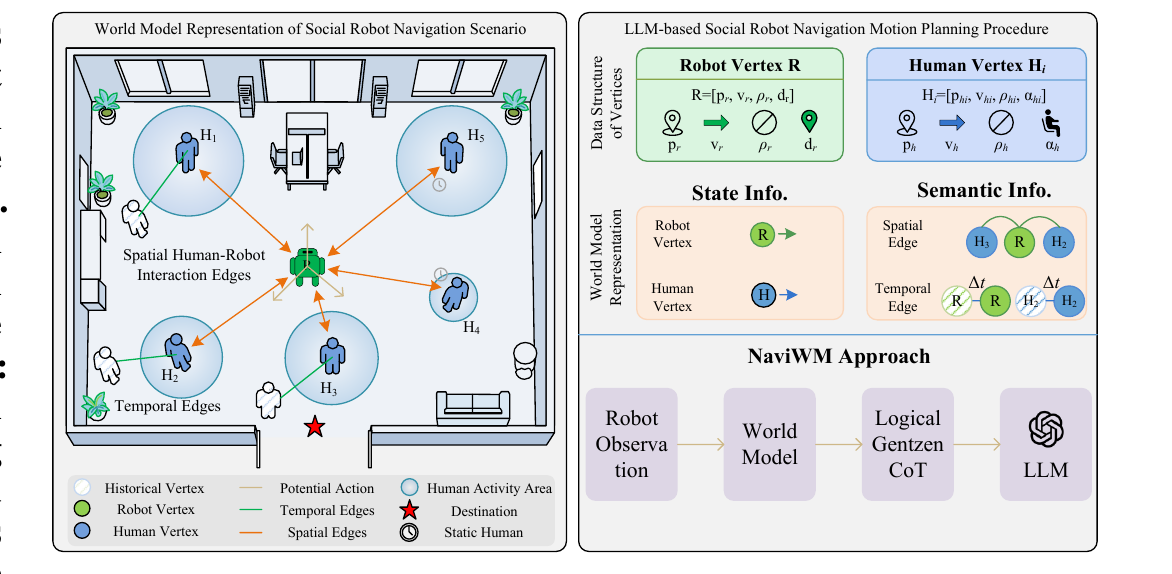
The unifying world-modeling contribution: perception exports object masks, extents, global pose, relations, and uncertainty — the state that later planners can check.
SELP: generating safe and efficient task plans for robot agents with large language models
LLM · Planning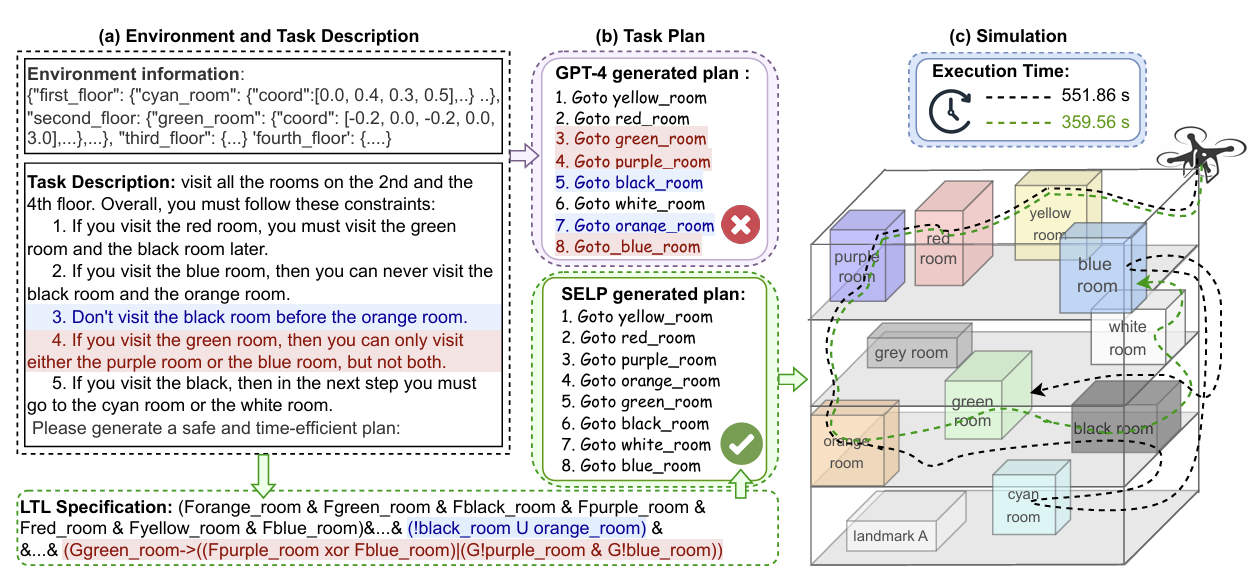
- The failure mode: a language model can emit a plan that is syntactically fluent but violates ordering, reach-avoid, safety, or resource constraints.
- The SELP move: translate the task requirement into a temporal-logic specification, track feasible prefixes during generation, and mask tokens that would make the plan unsatisfiable.
- What changes conceptually: the LLM becomes a proposal mechanism inside constrained search, not an unchecked robot planner.
He also discussed uncertainty-aware world modelling as a key component of his autonomy stack — one of the rising keywords at this conference, with AGIBOT dedicating an entire competition track to it here at ICRA 2026.
Hesheng Wang — learning to navigate: from scene understanding to decision making

In case you haven’t noticed yet, SLAM is a core technique in robot navigation :) A dense showcase of work from his lab at Shanghai Jiao Tong University:
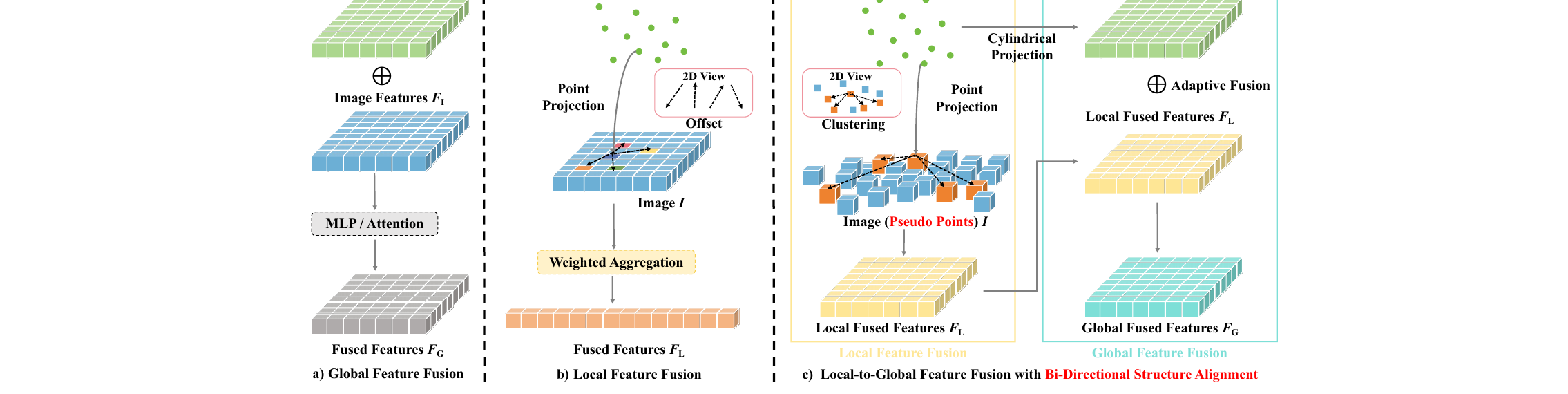
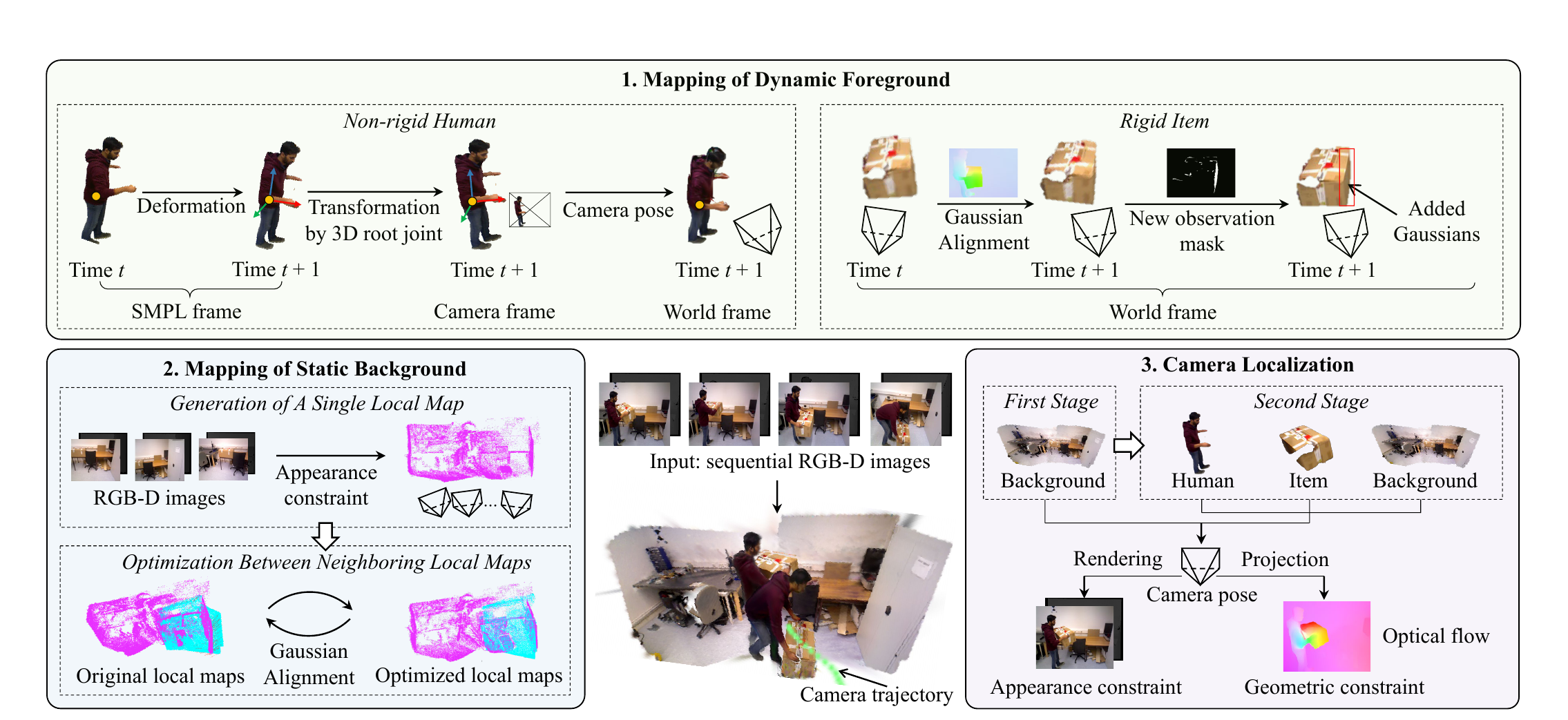
SNI-SLAM++: tightly-coupled semantic neural implicit SLAM
SLAM · Semantic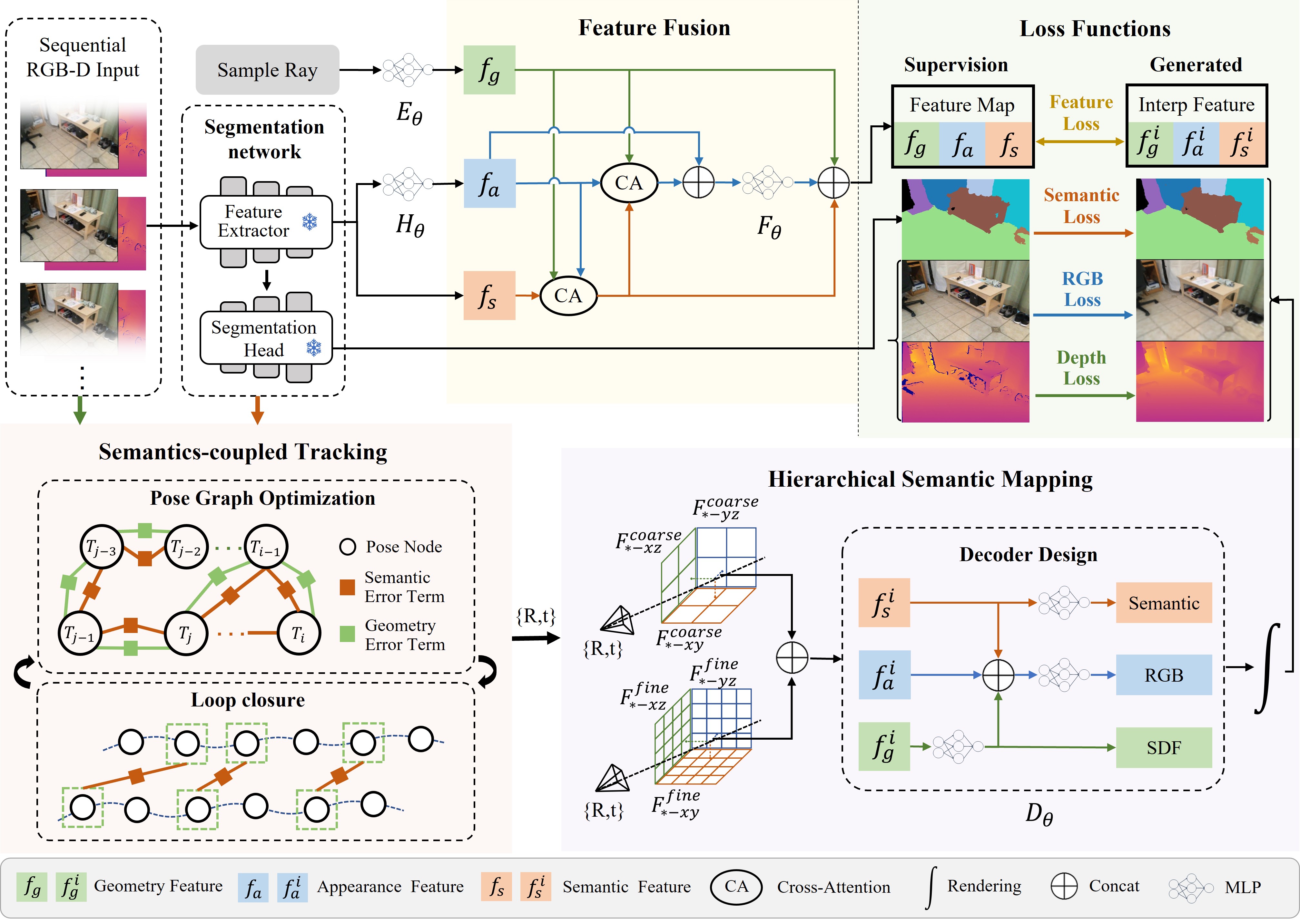
NRGS-SLAM: deformation-aware 3D Gaussian SLAM
SLAM · Medical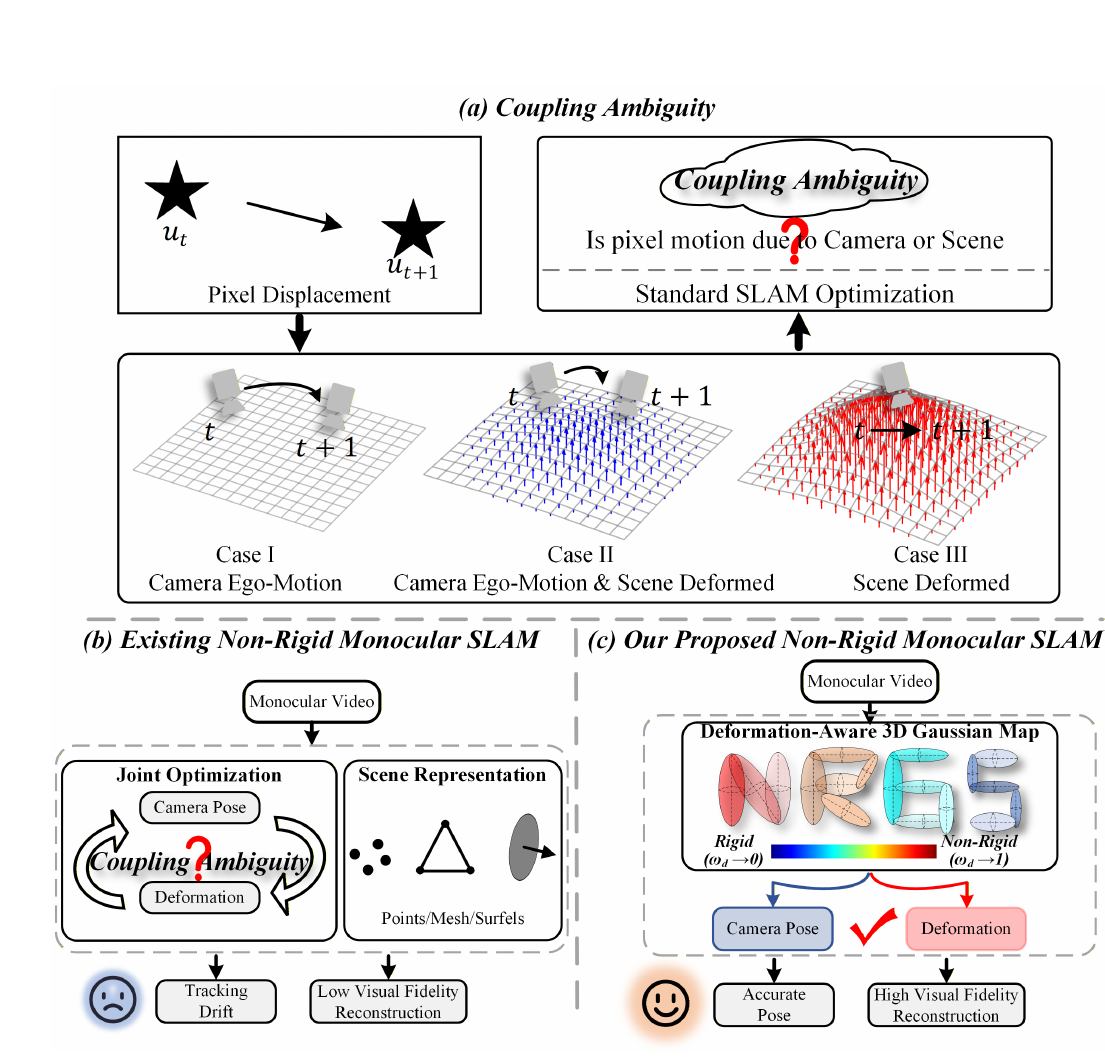
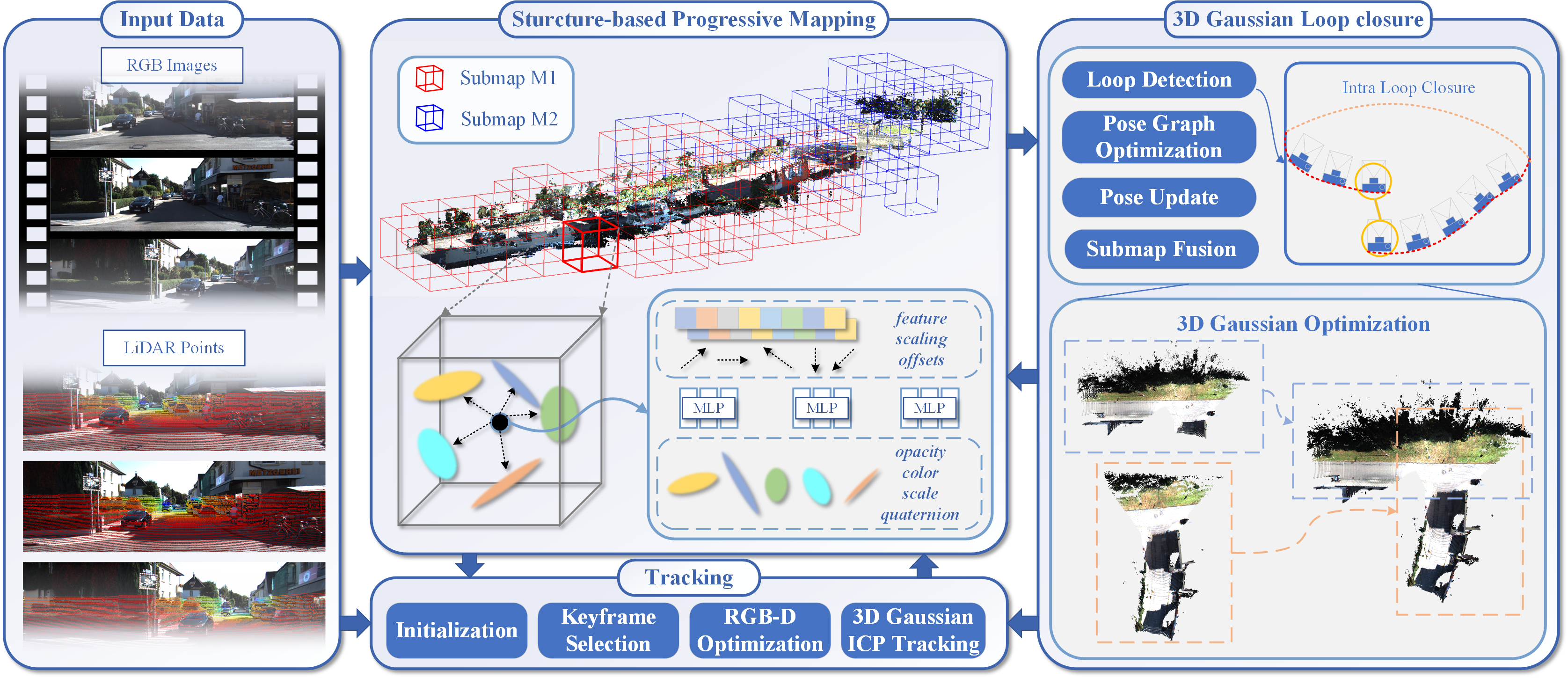
Awards talks: SA-VLM v2 — VLMs that help people
I’ve seen quite some works on VLMs this week, but shout-out to the very cool use case at the awards talks. We usually see visual SLAM as the base of autonomy for different robotic applications — but what about using it to help people?
SA-VLM v2: useful, comprehensive, and concise guidance for guide-dog robots assisting the visually impaired
VLM · Accessibility
SA-VLM v2 presented at the ICRA 2026 awards talks.
Day 3. Posters, Carlone, Barfoot, and how to talk to humans
Morning posters and Robot Perception I
A few things that caught my eye while wandering the poster hall:
GFreeDet2: Exploiting Gaussian Splatting and Foundation Models for RGB-based Model-free 2D and 6D Detection of Unseen Objects
Detection · 3DGS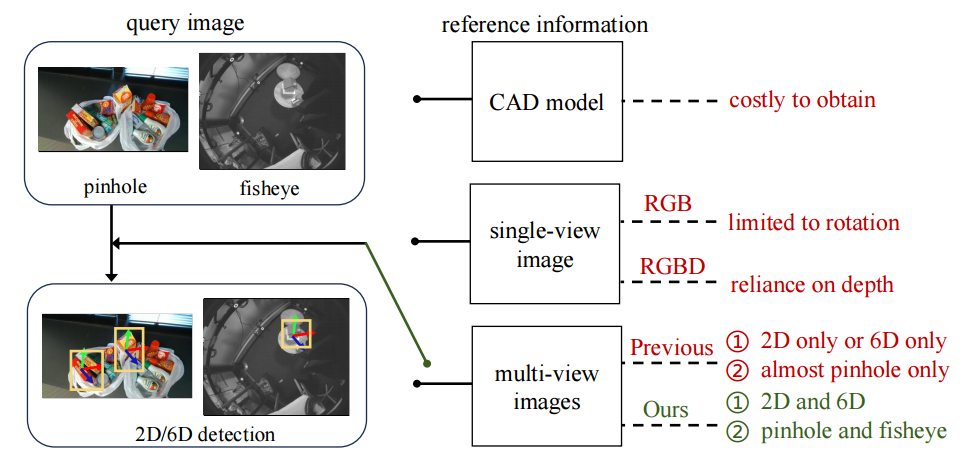
From the Robot Perception I session:
Sparse Variable Projection in Robot Perception: Exploiting Separable Structure for Efficient Nonlinear Optimization
Optimization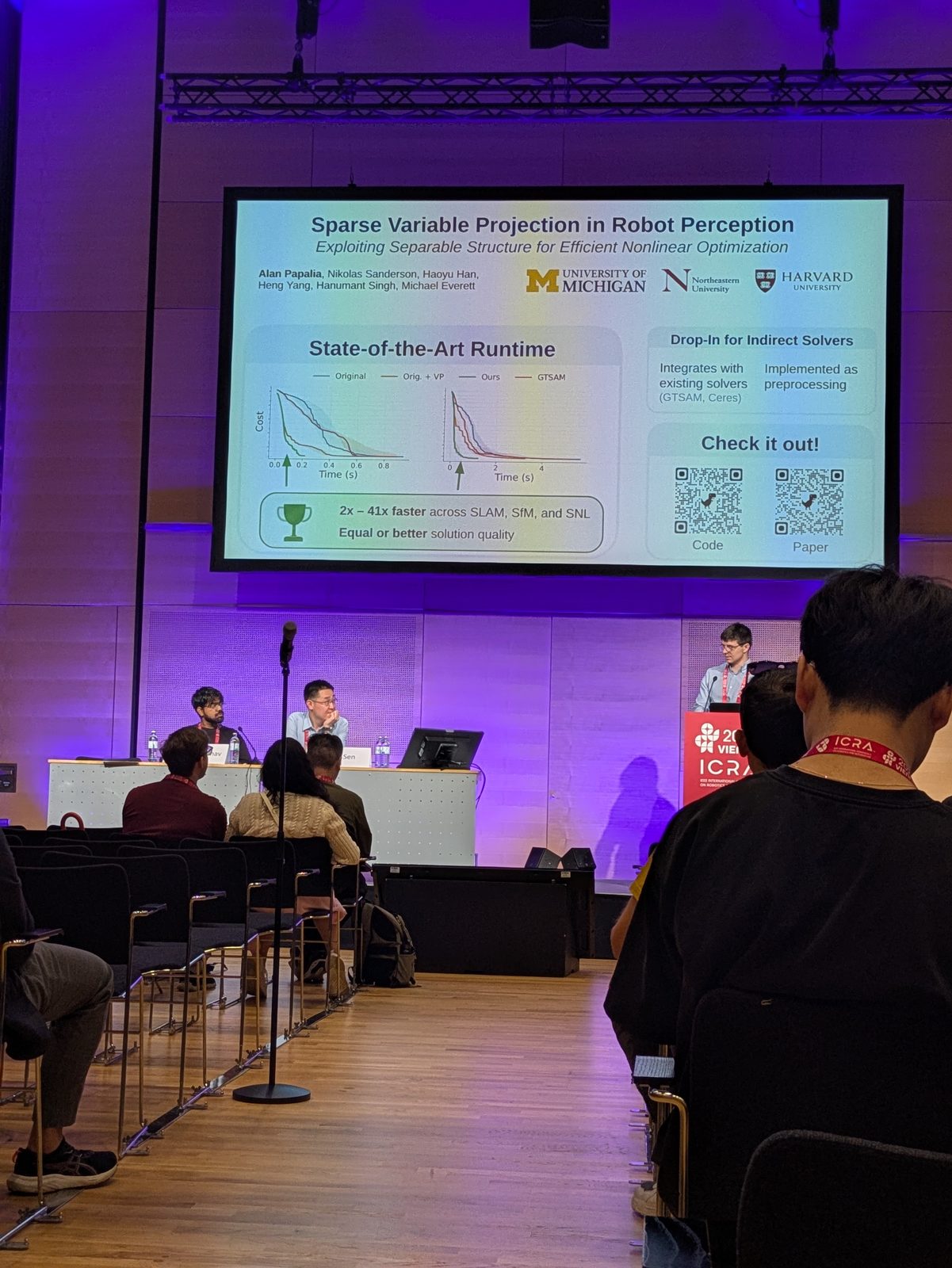
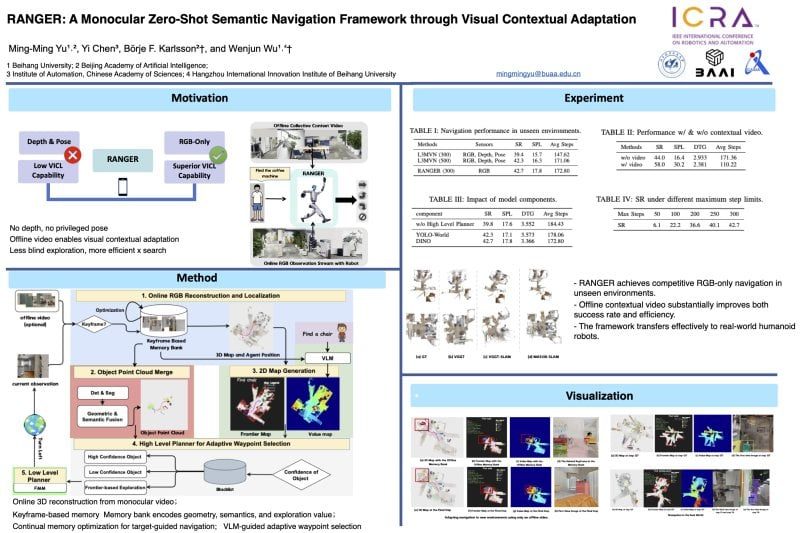
RANGER: A Monocular Zero-Shot Semantic Navigation Framework through Visual Contextual Adaptation
Navigation · Zero-Shot




K.1. Luca Carlone — from SLAM to spatial memories

As he said, “Classic SLAM is a huge success story”. SLAM algorithms have long been stablished at this point in history. However, classic SLAM systems are complex and need fine-tuning. From that perspective, a key advancement that learning-based algorithms have allowed is much simpler, even uncalibrated setups. Luca’s talk was a walkthrough their advances on SLAM, from adding learnt modules, to add further layers of abstraction on top of it, to the point of turning it into an actionable element that allows the robot to navigate and have a “memory”. The talk was divided into three sections:
- Maps: from classical SLAM to geometric foundation models.
- Memories: from mapping to semantic episodic memories.
- Tasks: towards task-driven memory representations.
1. Maps — from classical SLAM to geometric foundation models
On VGGT-based SLAM:

Understanding the Impact of Geometric Foundation Models on Vision-Language-Action Models
Foundation · VLA
2. Memories — from mapping to semantic episodic memories

“Memory is the ability to encode, store, and retrieve general information about the environment, learned facts, and past experiences.”
Beyond mapping — from maps to memories:
Hydra — real-time 3D scene graphs
Scene Graphs
DAaaM — Describe Anywhere, Any Moment
Captioning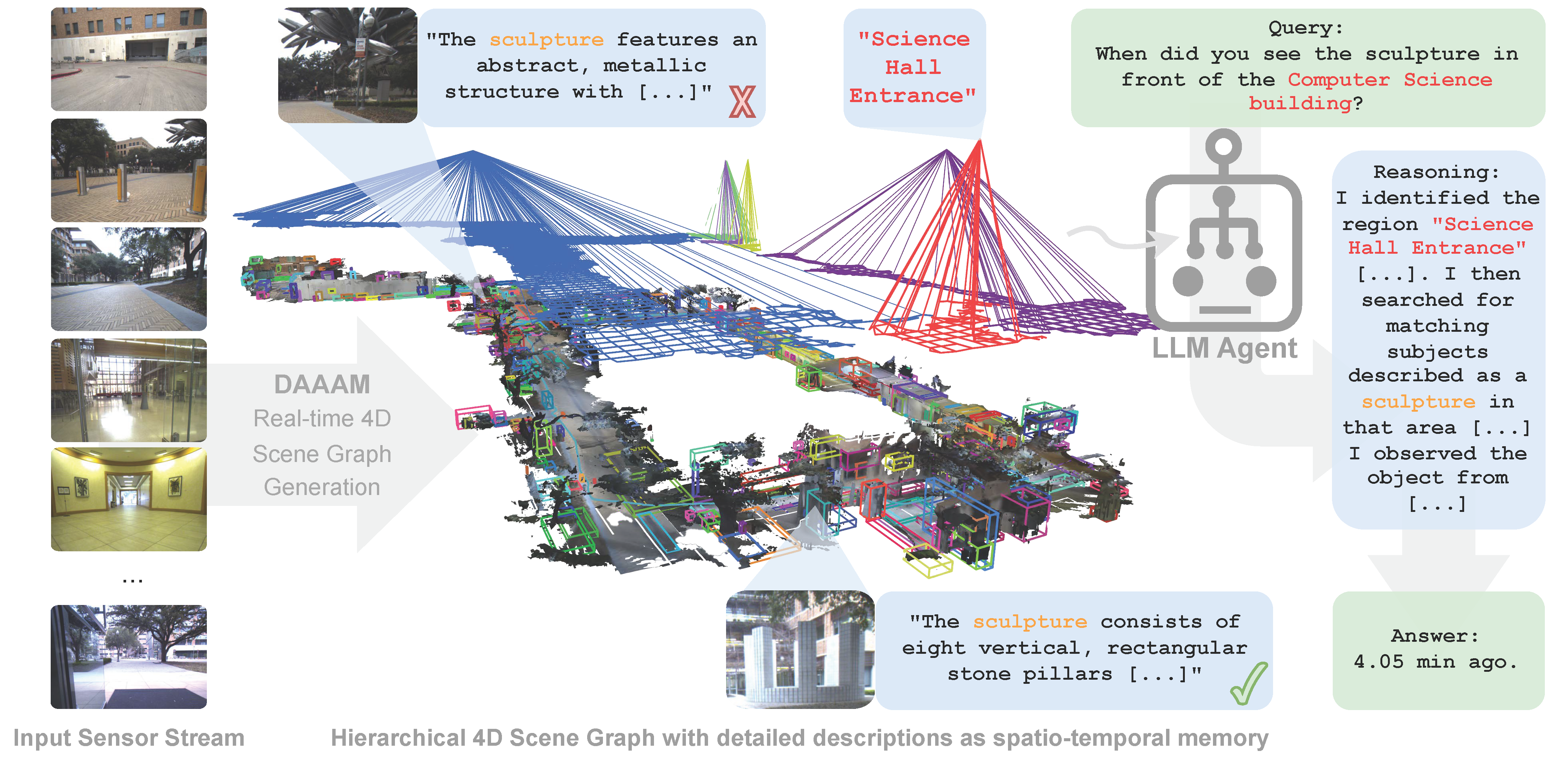
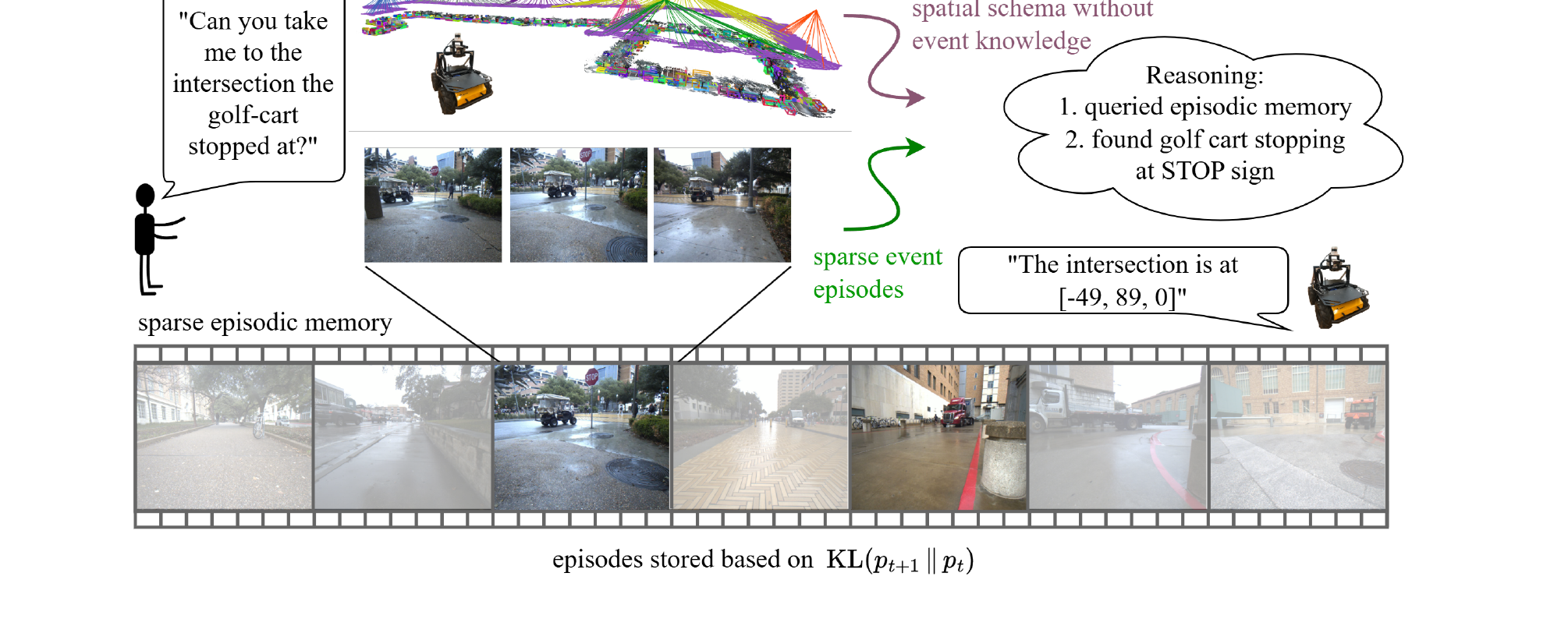
3. Tasks — towards task-driven memory representations
Clio & Found-it — task-driven memory
Task-driven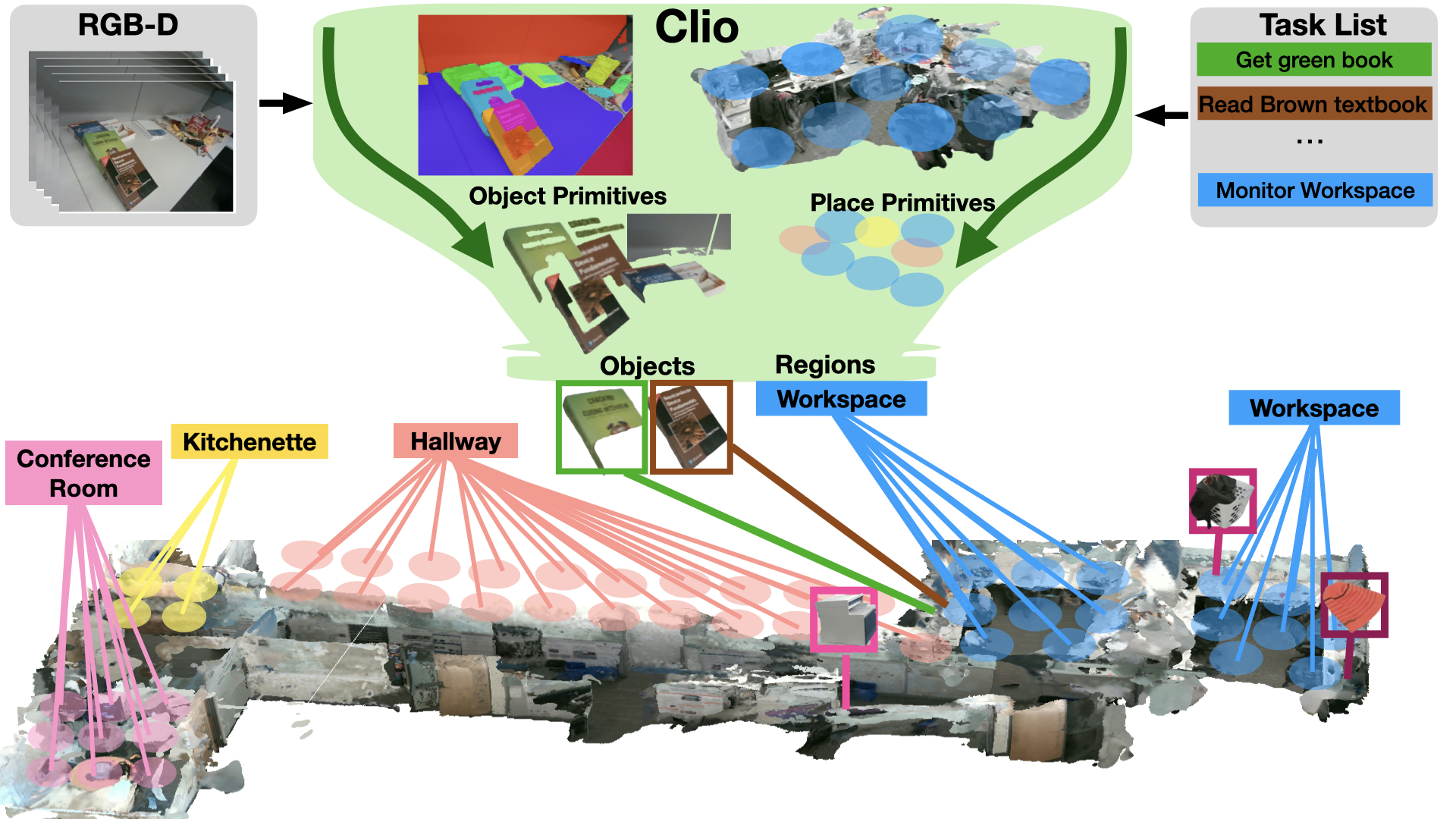
And to close, a quote: “The next generation of robots will require task-driven memory systems powered by foundation models.”
Amazing that so many of these resources are open — the mentioned works live in the MIT-SPARK GitHub org, and there’s also the SLAM Handbook!!
K.2. Tim Barfoot — why field robotics still matters

The talk was a showcase of the field experiments they carry out — like localization on an ice surface, which worked quite well, testing robots that one day might go through the Arctic. You can check out the resources at their lab website, such as a map of the places they’ve been and the datasets they’ve collected.
Science Communication Crash Course

A panel on how to communicate your science in a more engaging way, with Sabine Hauert (University of Bristol & Robohub), Ella Scallan (Robohub), Evan Ackerman (IEEE Spectrum) and Kohava Mendelsohn (IEEE Spectrum).
The strongest emphasis was on making it human. Sure, we’re talking about robots — but the developers behind them are people too. The story isn’t just the machine; it’s the people who built it, why they cared, and what they struggled with. That’s what an audience actually connects to.
A few takeaways:
- Lead with the human, not the hardware. People remember people. Frame the work around the person and the motivation, then bring in the robot.
- Drop the jargon. If your grandparent can’t follow it, neither can most of your audience.
- IEEE Spectrum is approachable. It’s a more laid-back magazine for science and robotics, and they’re always open to collaborating with scientists to write an article — so if you have a story worth telling, reach out.
Tutorial: Building, Running and Deploying Modern Software Tools for Robotics

Many years ago, as a student at a university with not so many resources, the nonsense of the equations and numbers we were seeing in class turned into something tangible thanks to the Robotics Toolbox, and understandable thanks to the book behind it (I’m a practical learner, ok?). I can’t put into words what it felt like to be at this keynote tutorial from Peter Corke and Tobias Fischer, and it being a practical class just like the ones I had at my Bachelor’s.
Luca Carlone said at his keynote that this is one of the most exciting times to be a robotics researcher. I fully agree, and one of the reasons is exactly this: the number of open libraries and resources that make robotics approachable. Seeing the history of how all these tools evolved, and the new tools that exist today, is a great reminder of this privilege. Being here is such a privilege!
Anyway, whether you were here or not, all material is on GitHub.
Arts & Robotics

The photo above is disarming II by Emanuel Gollob (University of Arts Linz / Creative Robotics): a freely placed industrial robot arm durationally learning locomotion on a gym mat. The piece plays with the ambiguity of disarming as both physical detachment and emotional attachment — locomotion as a primal, post-birth instinct and ultimate act of independence, attempted by a limb that was never made for it. Its reinforcement learning is deliberately slowed down and partially deprived of efficiency, leaving space to watch your own projections at work: parallel to the familiar dystopian plot of technological autonomy, witnessing these first clumsy tries may awaken compassion, or even a certain emotional bond.
Day 4. Robot learning, planning and foundation models
Keynote session 5 was a four-speaker block on robot learning, planning, and foundation models.
K.3. David Hsu — scalable robot decision making in the open world

Planning and plan prediction with foundation models.
Open-world challenges: scalability and uncertainty — complex appliances for the robot to interact with. The robot can be thought of as a function mapping inputs from perception to outputs for actions.
- The classic era is model-based: state estimation, planning and control. The challenge is acquiring good models.
- The deep learning era is data-driven: we acquire data for the robot to learn a policy. Successful, but the challenge is acquiring data — and anything changing on the robot. How to generalize?
- The foundation model era: we have to lay out a strategy over a two-dimensional space. One axis is representation, the other is reasoning. We’re going to see the benefits of structured representation.

Papers mentioned:
Robot operation of home appliances by reading user manuals
Manipulation · LLM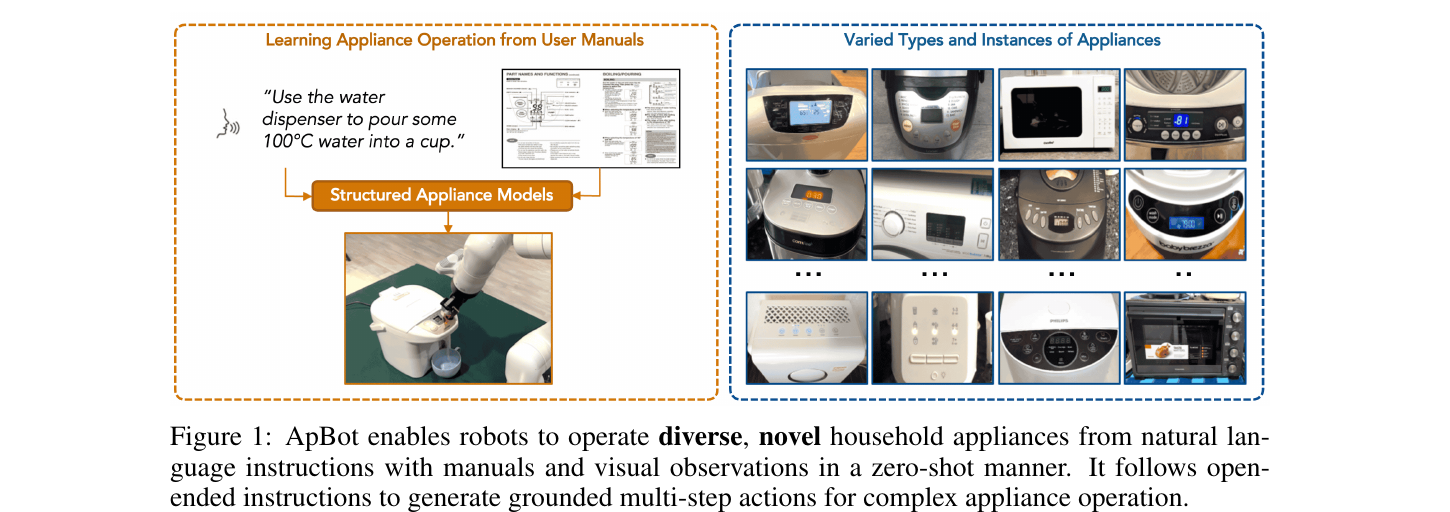
K.4. Stefanie Tellex — robot programming

What is the way to specify a robot’s task? “Someone has to sit next to the robot and make it do the thing.” Learning from demonstrations is limited to the speed of the demonstration; reinforcement learning needs a lot of data. They combine both: extract the behaviours from demonstration, improve with RL.
Papers mentioned:



K.5. Noémie Jaquier — traveling the robot learning manifold: a tale of geometries and inductive biases

Deep learning is now everywhere, and we are very used to just plugging in a network (a CNN, RNN, transformer, whatever) and hoping it works. Even more so with the rise of foundation models. But networks are encoding information in some dimensionality, and whether that dimensionality fits your problem or not matters a lot. What they propose: use the geometry of the robot as an inductive bias to constrain the network to the right dimensionalities — from geometry, to physics, to control theory.
Riemannian flow matching policy for robot motion learning
Motion Learning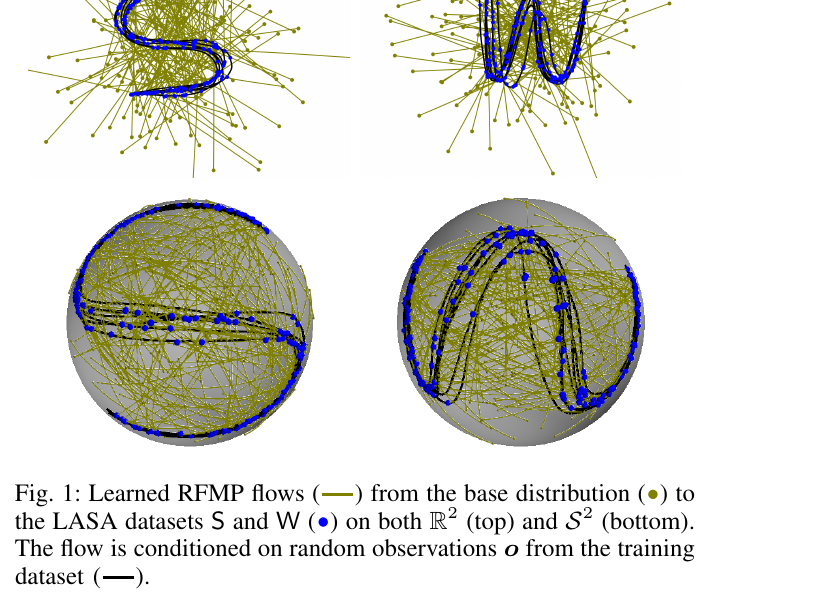
Symmetries here and there, combined everywhere: cross-space symmetry composition in robotics
Equivariance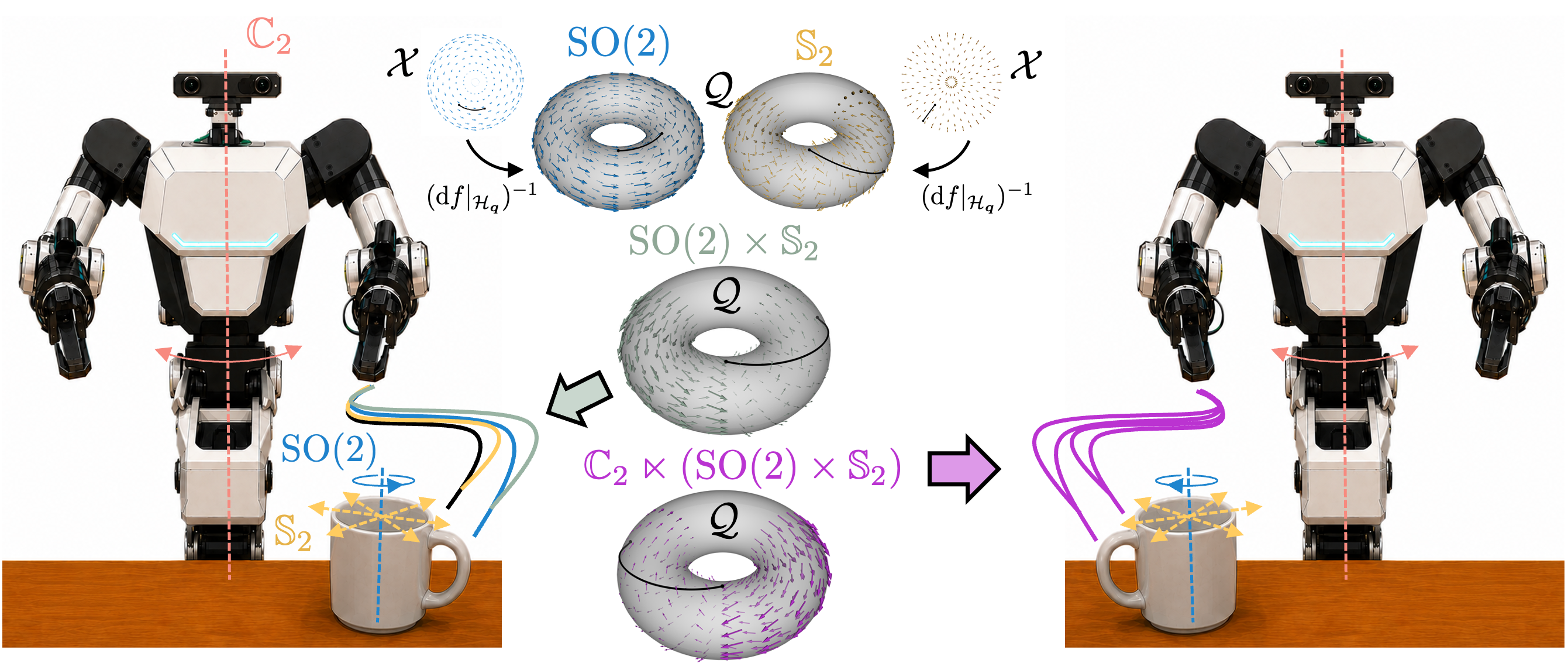
An interesting question from the audience: how many dimensions should the latent space have, and how do we beat the curse of dimensionality? More complexity needs more dimensions. How many? The answer is 42! Just kidding — it’s yet another hyperparameter to figure out ![]() Good luck!
Good luck!
On a side note, shout-out to the visuals in this talk — very pretty and very explanatory of complex concepts. My camera did its best at capturing them.
More papers mentioned:
And there is a book ![]() !
!
K.6. Paolo Robuffo Giordano — intrinsic robustness


A journey from control-aware planning to robust robot learning.
Awards

Expo

Random expo notes: camera + LiDAR rigs everywhere; MimosaX.
Day 5. Workshops: Robots Meet Prior Maps
The day started with an intro talk by Skydio… because I was in the wrong room :P Before I noticed and relocated, I learned what it takes to deploy autonomous robots at scale: autonomy, hardware reliability and manufacturing, support and regulatory readiness, and software & simulation — the talk focused on the latter. They run automated testing in CI, and deliberately didn’t move their Unreal Engine simulation to the cloud because they want to push the simulator boundary and keep it all integrated in CI. They simulate the gimbal, built their own ray-traced rendering, and use Google 3D tiles for map data (Paraverse). They’re hiring in Zurich.
Then, on to the actual Robots Meet Prior Maps workshop.
Maurice Fallon (Oxford) — where’s my glasses: identifying change in scene graphs over time

- Feed-forward reconstruction models give you perturbed scales — ScaRF-SLAM fixes them by combining classical visual SLAM with the foundation-model reconstruction, doing incremental map fusion and constantly refining the scale of the submaps. See also ov_secondary. Their preferred setup: VGGT with Depth Anything.
- Understanding to what degree the scene has changed matters, because change makes odometry struggle (fast-moving sensors too). They use a prior laser scan of the building.
- Upcoming paper (in writing): object-level change detection via semantic correspondence association in long-term multi-session mapping. For scenes where image detection isn’t precise, Gaussian splatting is not so successful — e.g. under significant lighting change. They found dense correspondence with DINO to work better there. LT-mapper is the previous work on this.
- The system they want to build: step 1, fuse depth from an external sensor (or estimate) to build a local map, with object segmentation to look for local dense features; step 2, semantic and geometric change detection.
Jen Jen Chung (UQ) — exploring interactions with object-level maps
Object-level maps to make grasping missions more efficient. Papers along the way: Learning affordance landscapes for interaction exploration in 3D environments (using the AI2-THOR interactive simulator), Learning affordances from interactive exploration using an object-level map, and TSDF++, a multi-object formulation for dynamic object tracking and reconstruction.
Abhinav Valada (Freiburg) — open-world autonomy: representations, mapping, interaction

How do we make autonomy reliable in the open world?
- Amodal perception: estimate the entire shape of objects regardless of occlusions — amodal panoptic segmentation.
- Class-incremental panoptic segmentation: don’t retrain for new labels, extend the knowledge.
- Open-vocabulary dynamic 3D scene graphs.
- What happens when you encounter never-before-seen objects? Predict that it’s an unknown object: PoDS, panoptic out-of-distribution segmentation.
- Rethinking lifelong SLAM — continual SLAM: instead of taking pretrained models and adapting them offline, adapt on the fly as the robot moves. Dual architecture: a generalizer and an expert, with an uncertainty-based sampling strategy (CL-SLAM). Train on Cityscapes, move to KITTI, then RobotCar, then back to KITTI — and check it still remembers. Follow-up at RSS 2023 adds monocular depth and panoptic segmentation (depth, semantic, panoptic error).
- ArtiPoint: articulated object estimation in the wild, with the Arti4D dataset — 45 egocentric videos of humans performing articulations.
- MoMa-LLM: mapping and structure for language-grounded mobile manipulation.
Luca Carlone (MIT) — from maps to memories: present and future of spatial AI

Foundation-model-first SLAM and 3D scene graphs — a longer version of his Day 3 keynote, with extra detail on VGGT-SLAM:
- Every single SLAM library has 50 to 100 parameters to tune :P VGGT works on uncalibrated videos — but it’s far from scalable, with limited processing ability.
- Two years ago they started simple: break the long trajectory into submaps (16 keyframes each), run VGGT on each, then align the submaps. Issue: artifacts. The mismatch comes from a fundamental reason — projective ambiguity. With calibrated cameras, the ambiguity is just the scale of the reconstruction; uncalibrated, it’s a full projective ambiguity, much more complicated: you confuse calibration errors for deformation of the scene, and each submap gets a different deformation.
- So instead of aligning submaps rigidly, they attach a homography transform to each submap: take pairs of aligning submaps (sequential + loop closures), get the relative homography, map each submap to a global homography, and optimize over SL(4) with GTSAM — dense RGB SLAM optimized on the SL(4) manifold.
- Next month, a new paper: assign a homography to each keyframe instead of each submap. Open question from the audience: how robust is VGGT-SLAM to scale inconsistencies in the depth prediction over time — perhaps the SL(4) alignment absorbs that error.
- Found-it addresses two big problems: going from RGB-D to monocular cameras, and dynamic tasks. Hydra is closed-set semantics, a rigid understanding of the scene; Clio addressed task-driven mapping but requires pre-specifying the tasks. They want to change tasks at runtime, hence Found-it.
David Hsu (NUS) — open scene graphs for open-world navigation
A personal journey of “maps” for open-world robot navigation.
José Luis Sánchez-López (Luxembourg) — tightly integrating semantic-relational priors into SLAM

What are scene priors? Previous knowledge, which he organized along four axes:
- Representation axis: scene level / environment type (the talk focused on indoors), geometric priors, semantic priors, relational/structural priors.
- Entity axis: the role of the scene — structure (floors, walls, etc.).
- Granularity axis: level of abstraction — observable/tangible vs. higher level.
- Source axis: implicit priors, previous-experience priors, BIM/CAD/architectural priors.
They have a survey on visual SLAM (MDPI). The core idea:
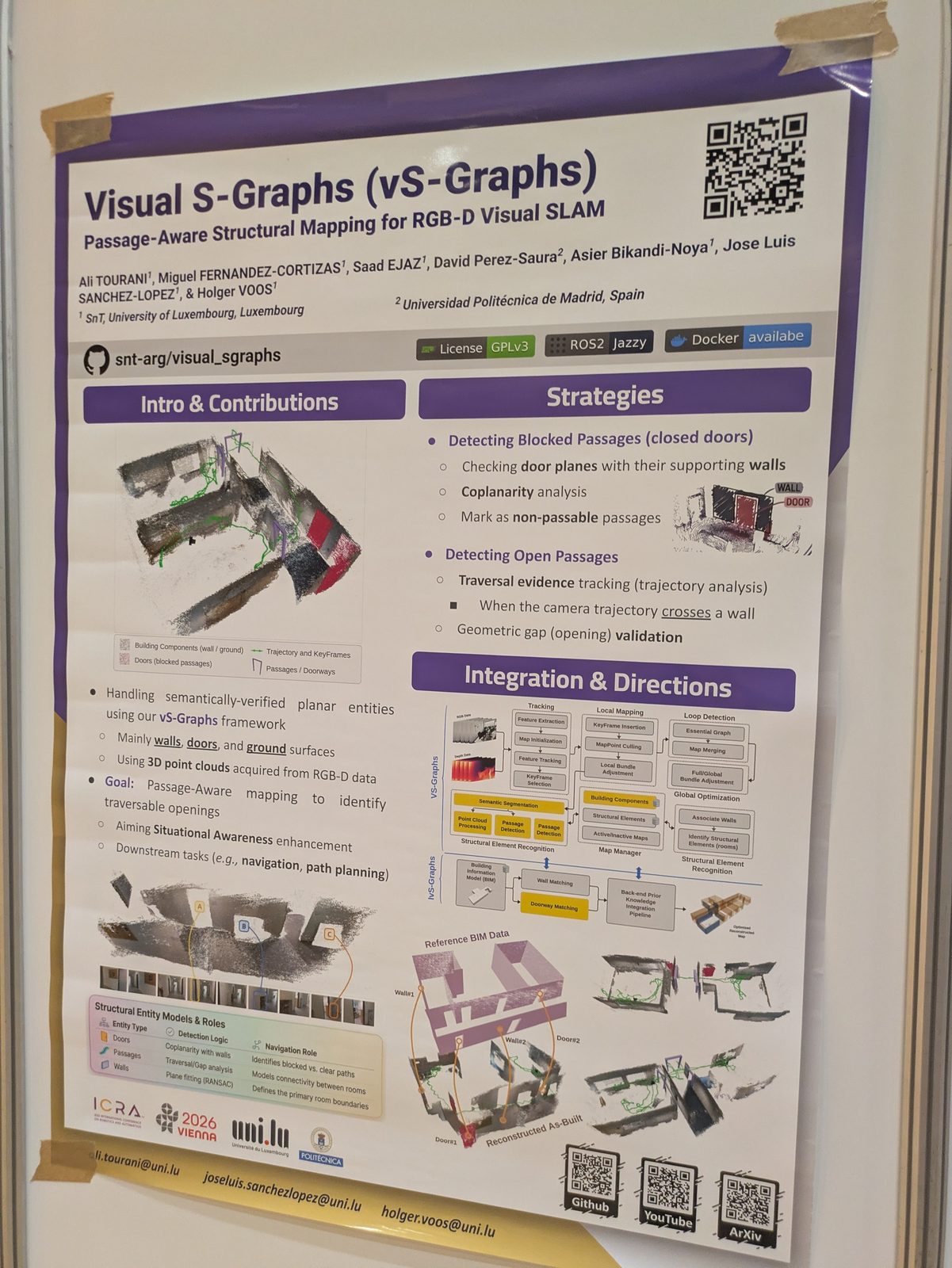
- We need to connect maps with scene graphs. Most works connect the SLAM output to a scene graph; they go for a tightly coupled approach because the two influence each other — the situational graph (S-Graph), encoding different levels of abstraction with hierarchical-semantic optimization. Code: snt-arg/visual_sgraphs.
- To encode it in a factor graph, they’re trying (ongoing) to replace the mathematical factors with graph neural networks → GNN S-Graphs 2.
- Previous-experience priors in a multi-robot, distributed setting: each robot builds its own S-Graph. With vision → viS-Graphs.
- Object entities in S-Graphs: they pretrain NeRFs with prior information — e.g. train on computers in general, then fine-tune to a specific computer: PRENOM.
- Dynamic entities in S-Graphs: incorporate prior knowledge of dynamic entities to improve pose estimation (under review).
Huan Yin (Hunan University, online) — BIM as a prior semantic map
Humans can navigate with simple semantic maps — robots should manage with a BIM model. Global localization from scratch: global registration / place recognition + a particle filter, with the COMPASS descriptor. Dataset: SLABIM / LiBIM-UST, a SLAM-BIM coupled dataset.
Javier Civera (Zaragoza) — mapping inside the human body

Endoscopy as the ultimate prior-less environment:
- Medical datasets either have privacy issues or are small.
- LightDepth (ICCV 2023): depth self-supervision from illumination decline in real colonoscopy. The physics: light vanishes with distance, and also depends on the angle of the light, the normal of the surface, the albedo of the surface, and the camera parameters (gain and gamma correction). They train a network that predicts the albedo, depth and normals of the surface to reconstruct it — all differentiable, so all errors can be propagated. The C3VD dataset serves as a synthetic ablation, just to demonstrate that it works.
- For localization, they synthesize sparse images and match against those. Feature extraction and matching was a problem back then — they used D2-Net (pre-SuperPoint era).
Floor notes and links
- VGGT-Ω doesn’t need loop closure.
- Map Anything.
Links collected:
- GrandTour dataset (ETH RSL / legged robotics).
- FindAnything: Open-Vocabulary and Object-Centric Mapping for Robot Exploration in Any Environment.
- Marco Job’s Depth completion in unseen field robotics environments using extremely sparse depth measurements (with Thomas Stastny, Eleni Kelasidi, Roland Siegwart, Michael Pantic — in the proceedings): a depth completion model for field robots that pairs monocular depth estimation with extremely sparse depth measurements to recover reliable scale in unstructured, low-texture environments.
Also from the floor: the Sevensense camera.
MM-SpatialAI workshop
The MM-SpatialAI workshop (Multi-Modal Spatial AI for Robust Navigation and Open-World Understanding) ran on day 1, and a keynote talk is up on YouTube. The keynote lineup:
- Alex Wong (Yale) — Unsupervised extension of multimodal depth perception across scenes and sensors.
- Hermann Blum (University of Bonn) — The future of mapping: beyond reconstruction.
- Dezhen Song (MBZUAI) — Proprioceptive localization: when everything else fails.
- Timothy D. Barfoot (University of Toronto) — Roads, forests, and lakes, oh my! New multi-modal datasets and some thoughts.
- Margarita Chli (ETH Zurich / University of Cyprus) — Robust perception for single- and multi-robot systems: are we there yet?
- Sebastian Scherer (CMU) — Multi-modal perception for resilient autonomy.
- Andrew Davison (Imperial College London) — From SLAM to spatial AI.
Posters
Every poster I photographed across the week, regrouped by topic — loosely following my topic map. Titles link to my photos; the last few I only caught afterwards, via the authors’ own LinkedIn posts.
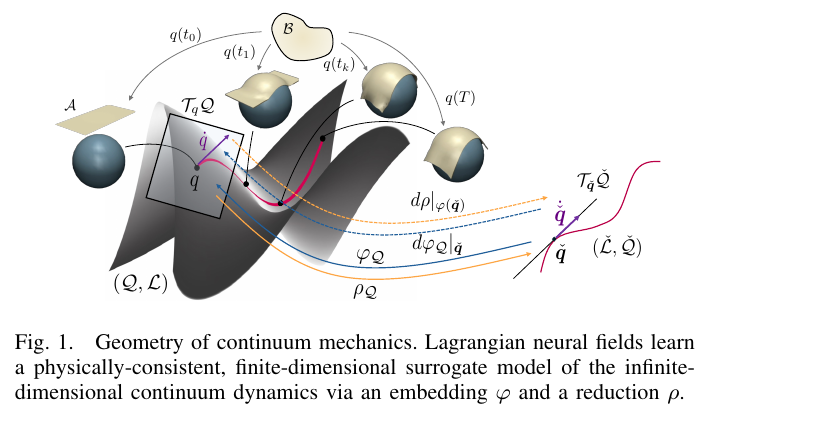
SLAM

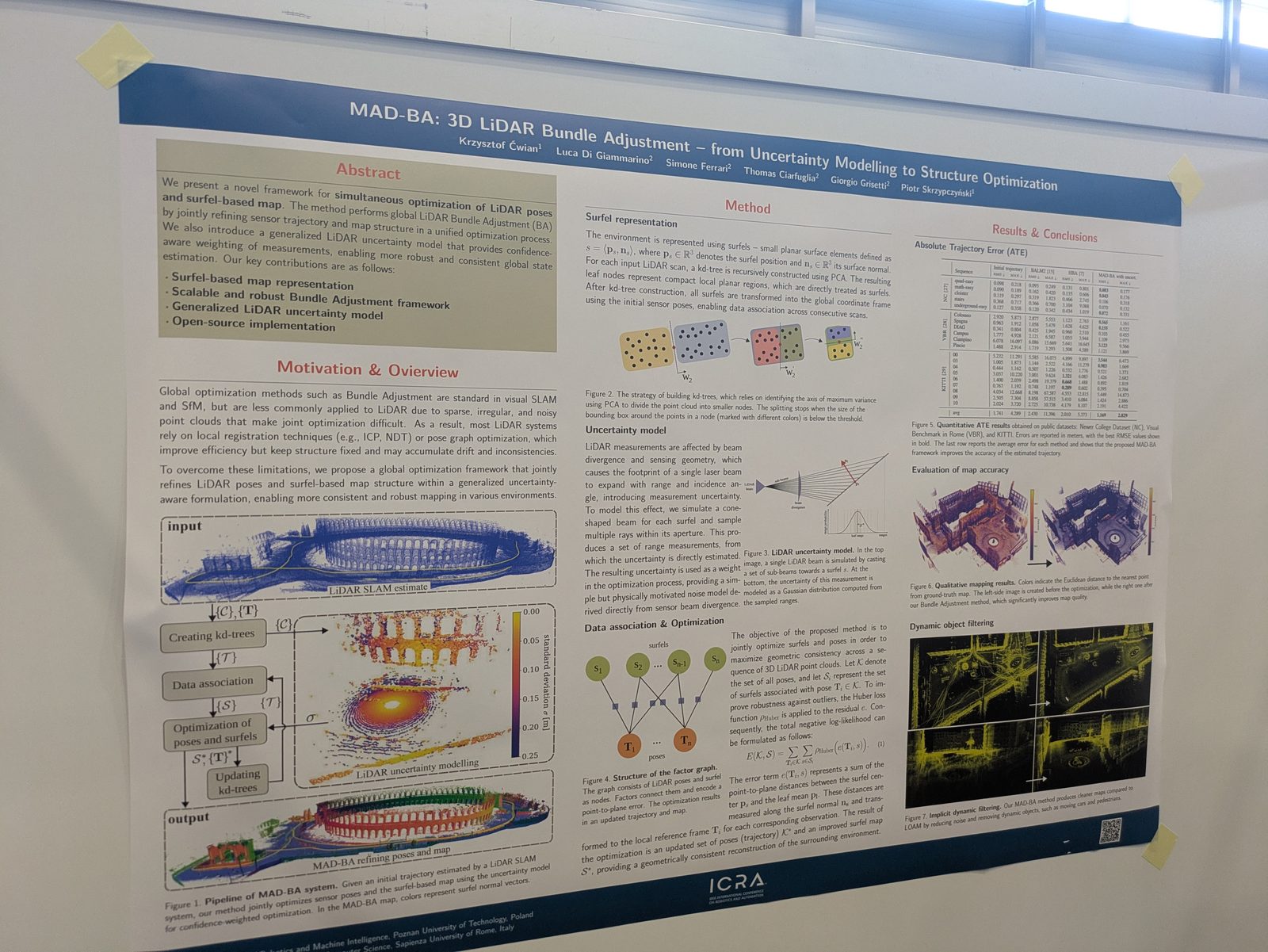
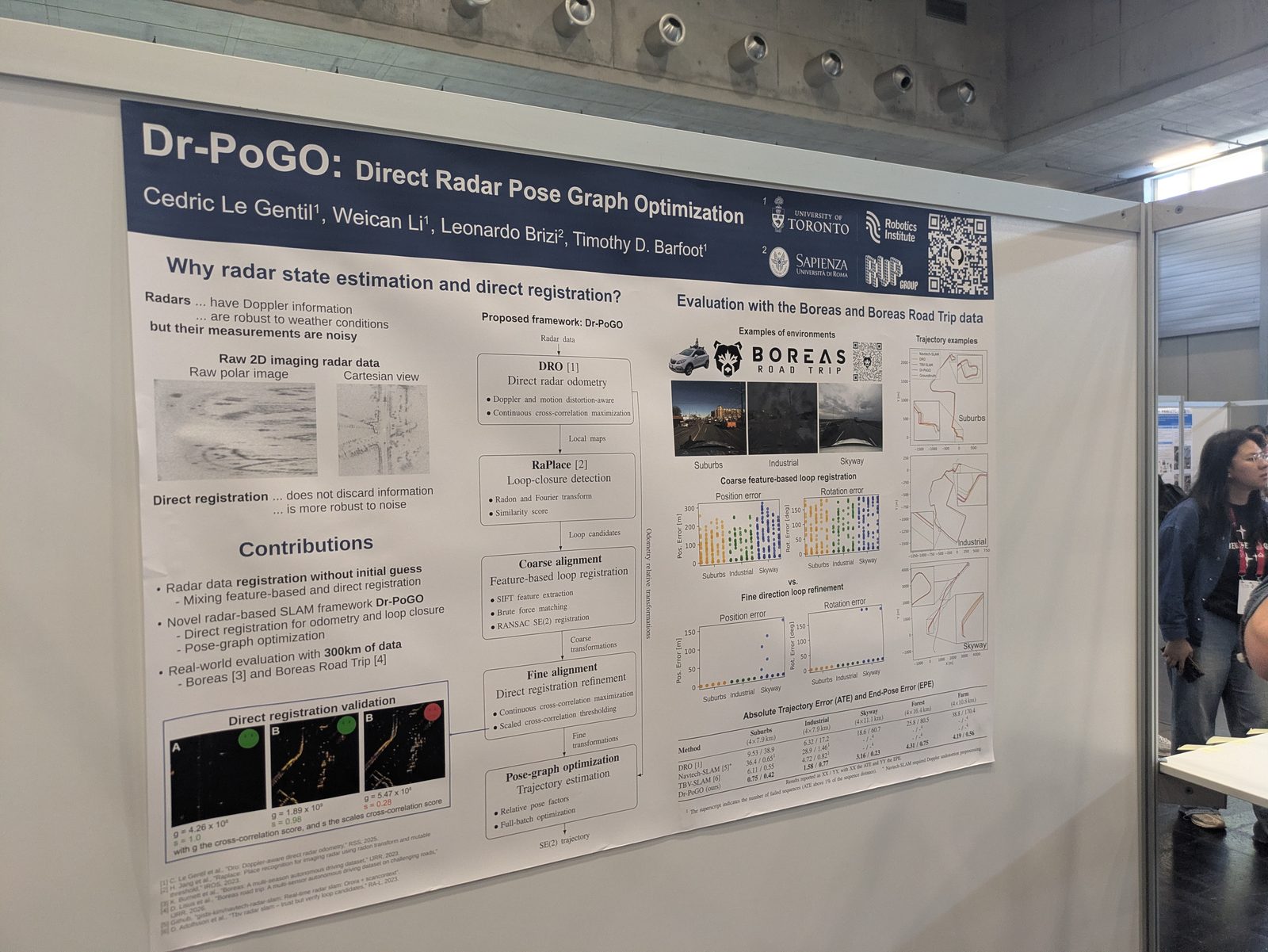
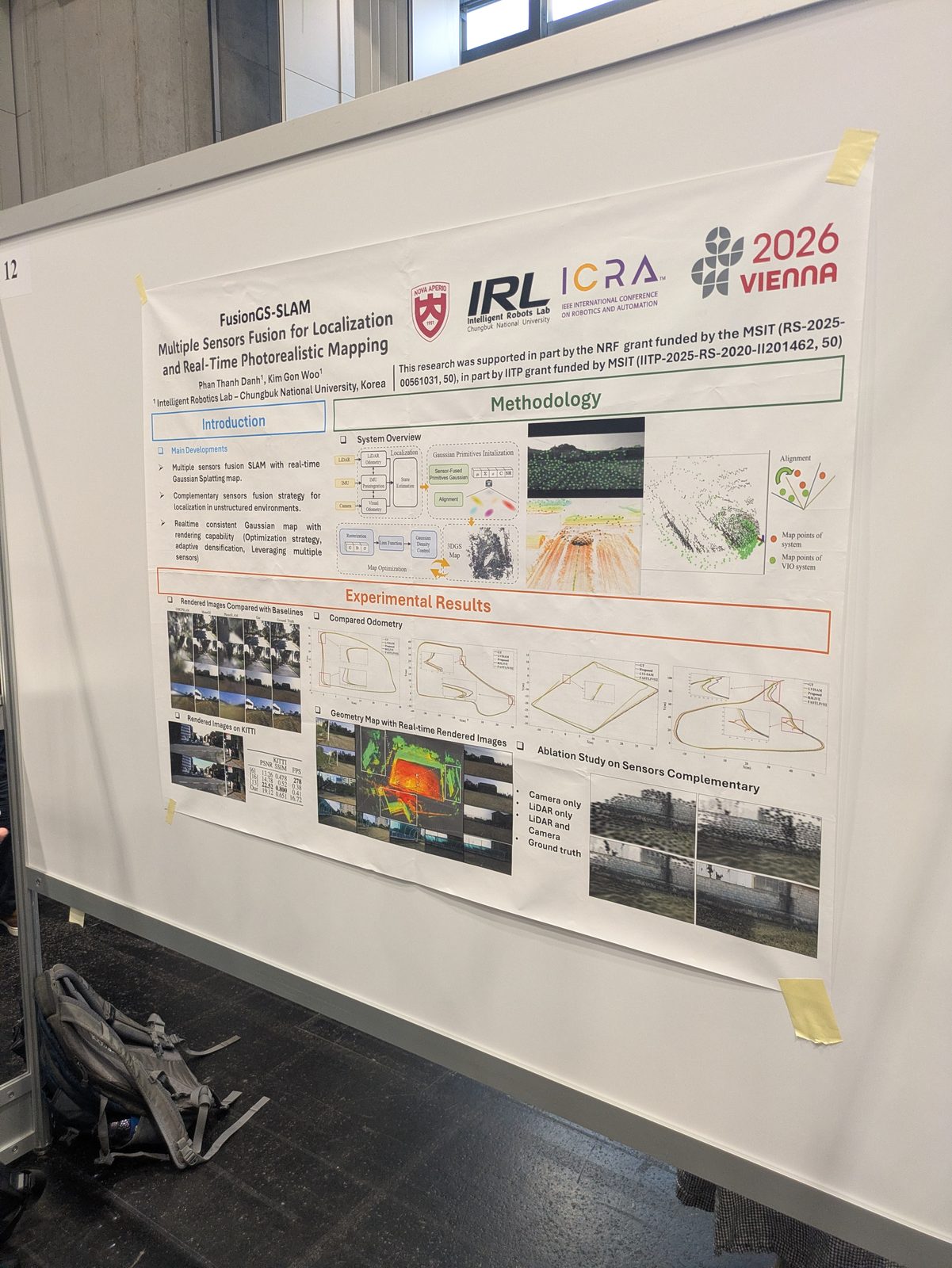



From left to right: Erdal Kayacan, Şebnem Sarıözkan, myself, Hürkan Şahin, and Davide Scaramuzza.
Multi-robot & collaborative SLAM
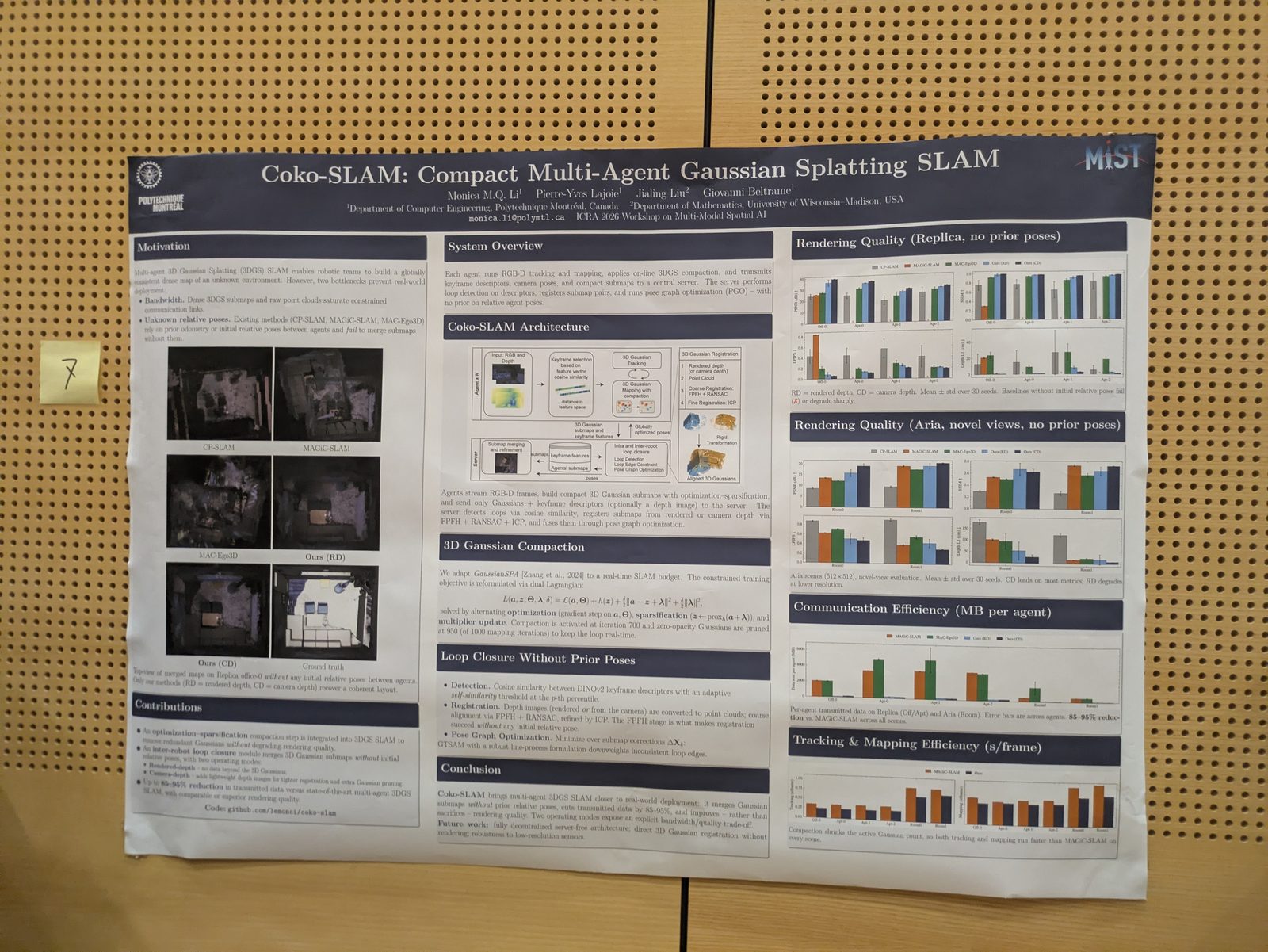
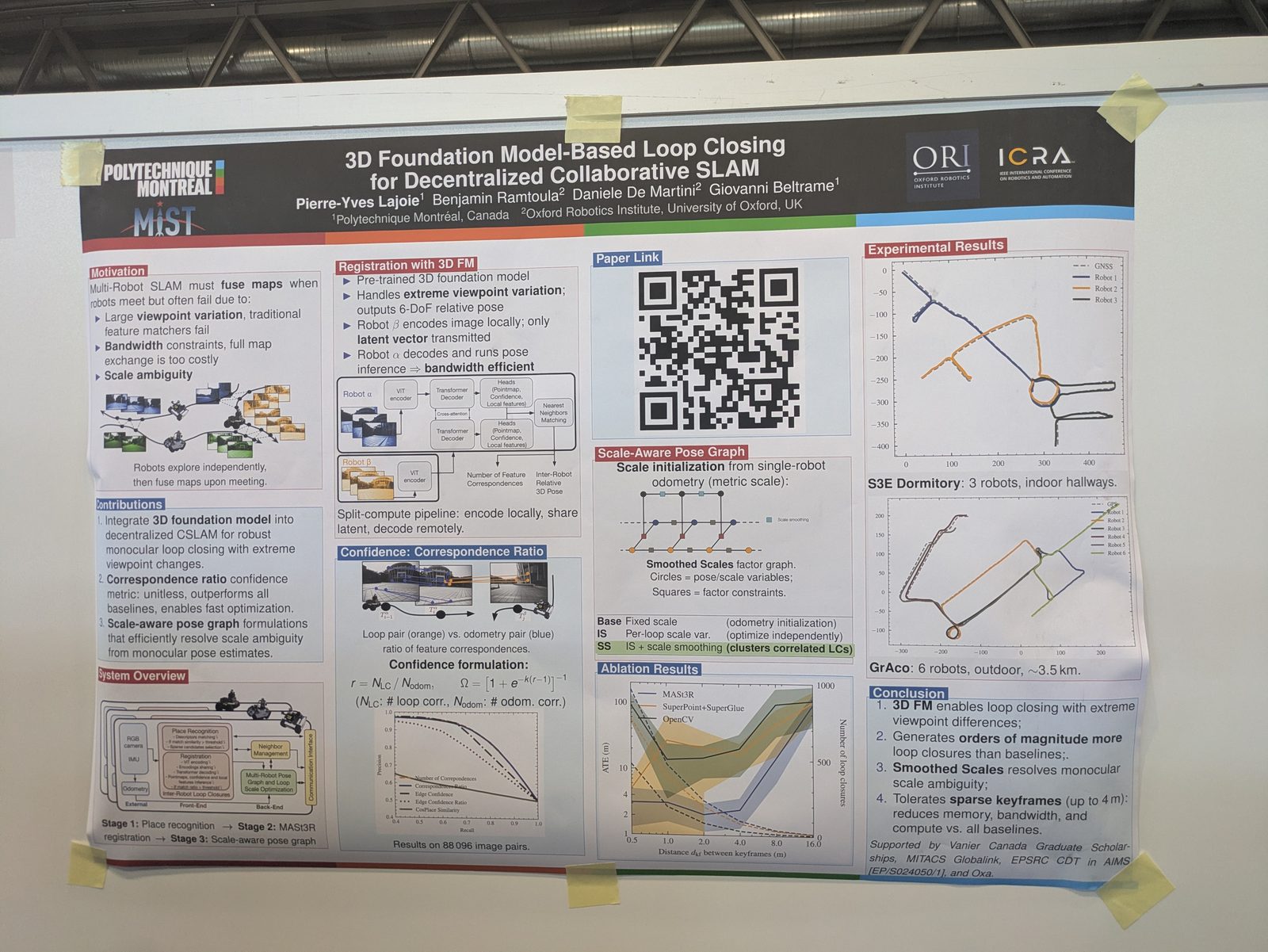

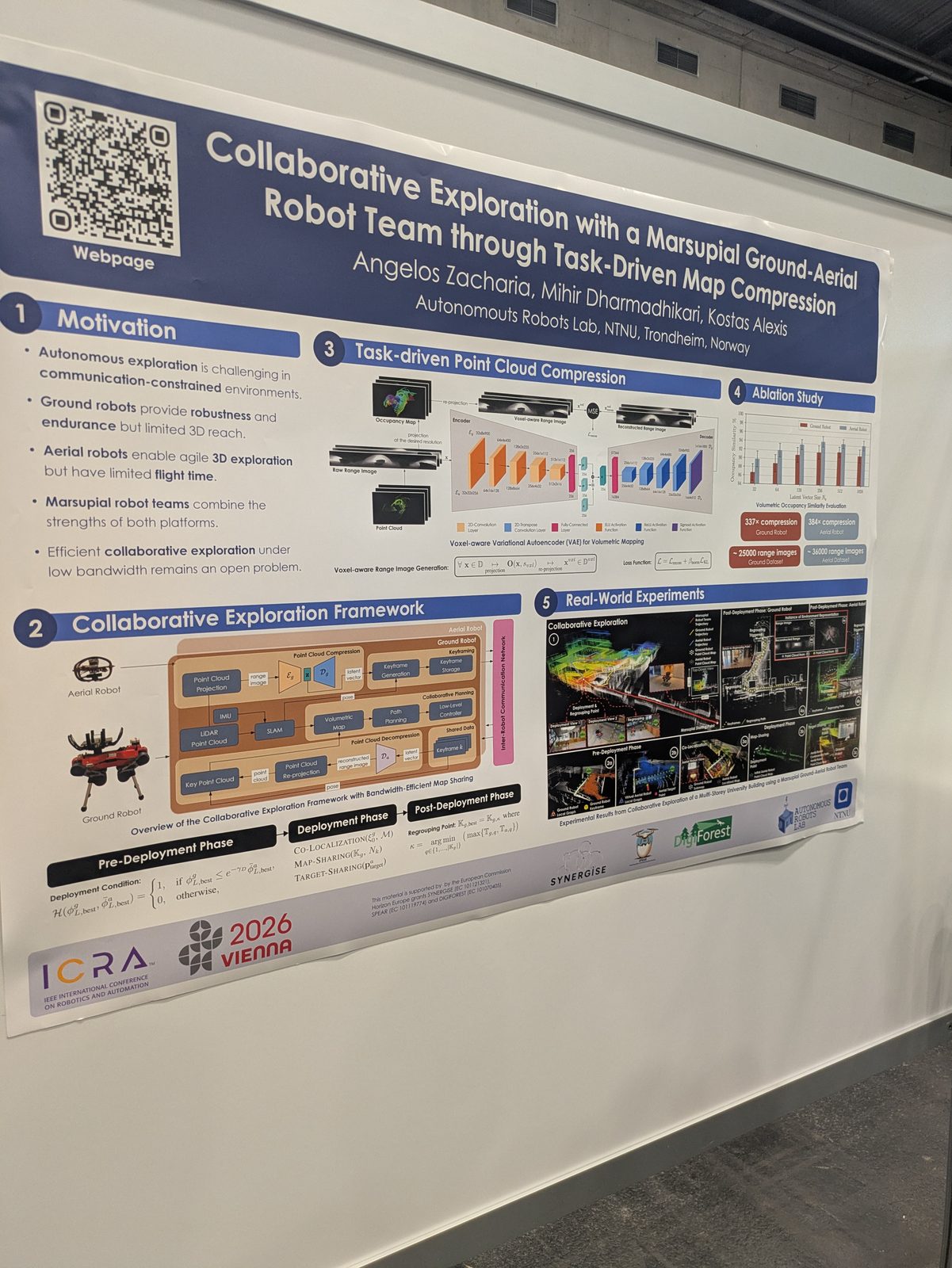

Localization & place recognition
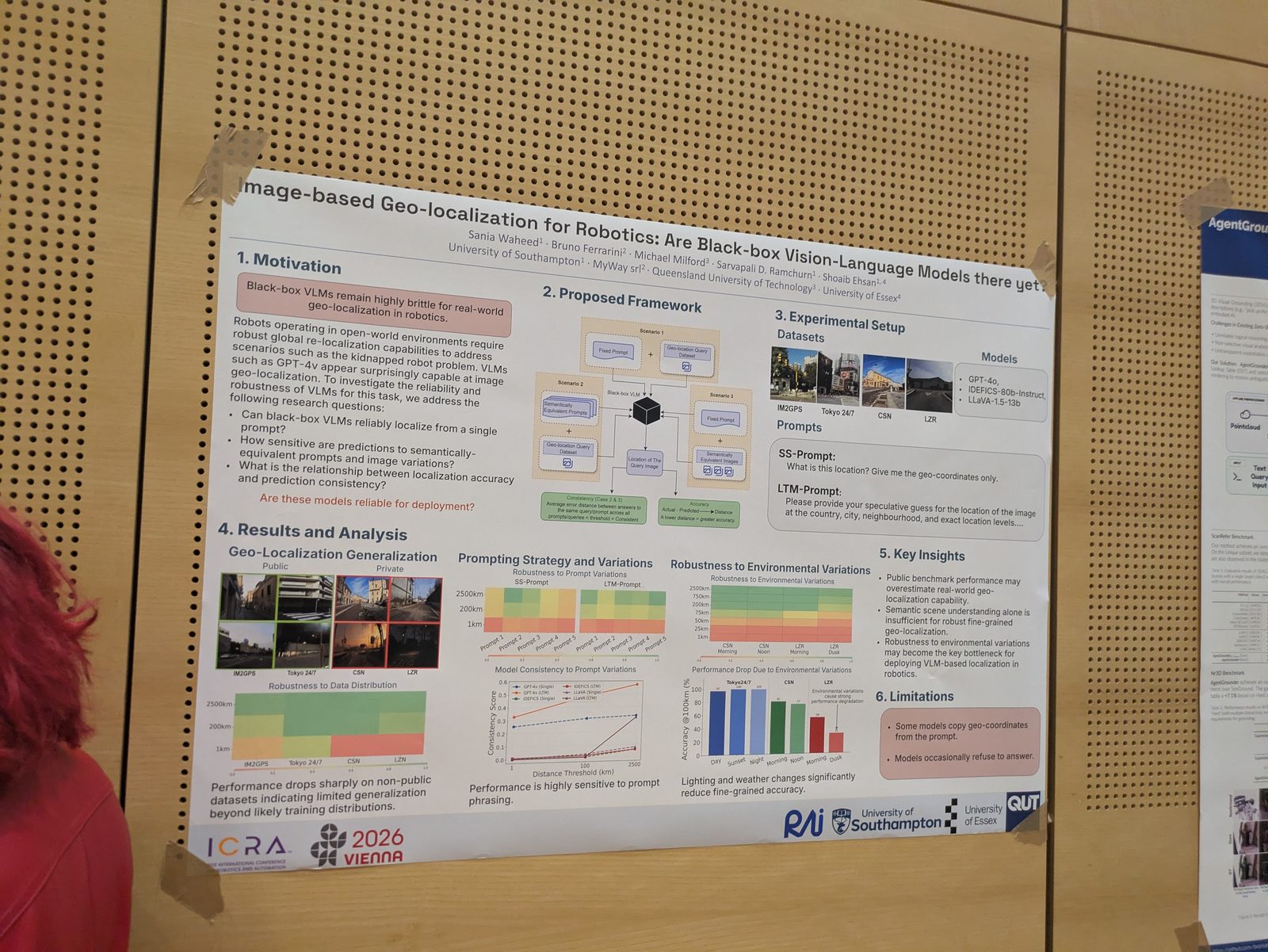
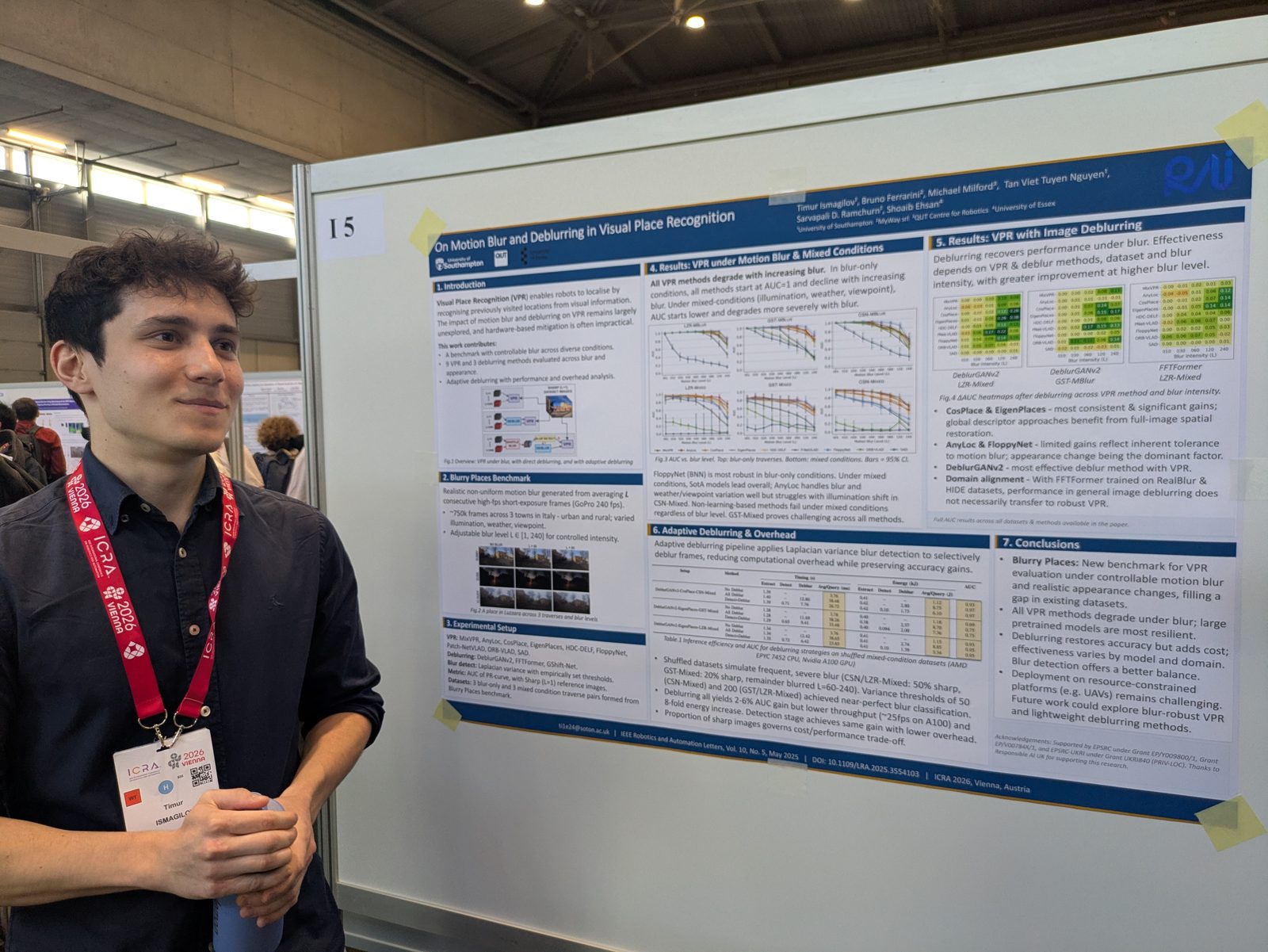

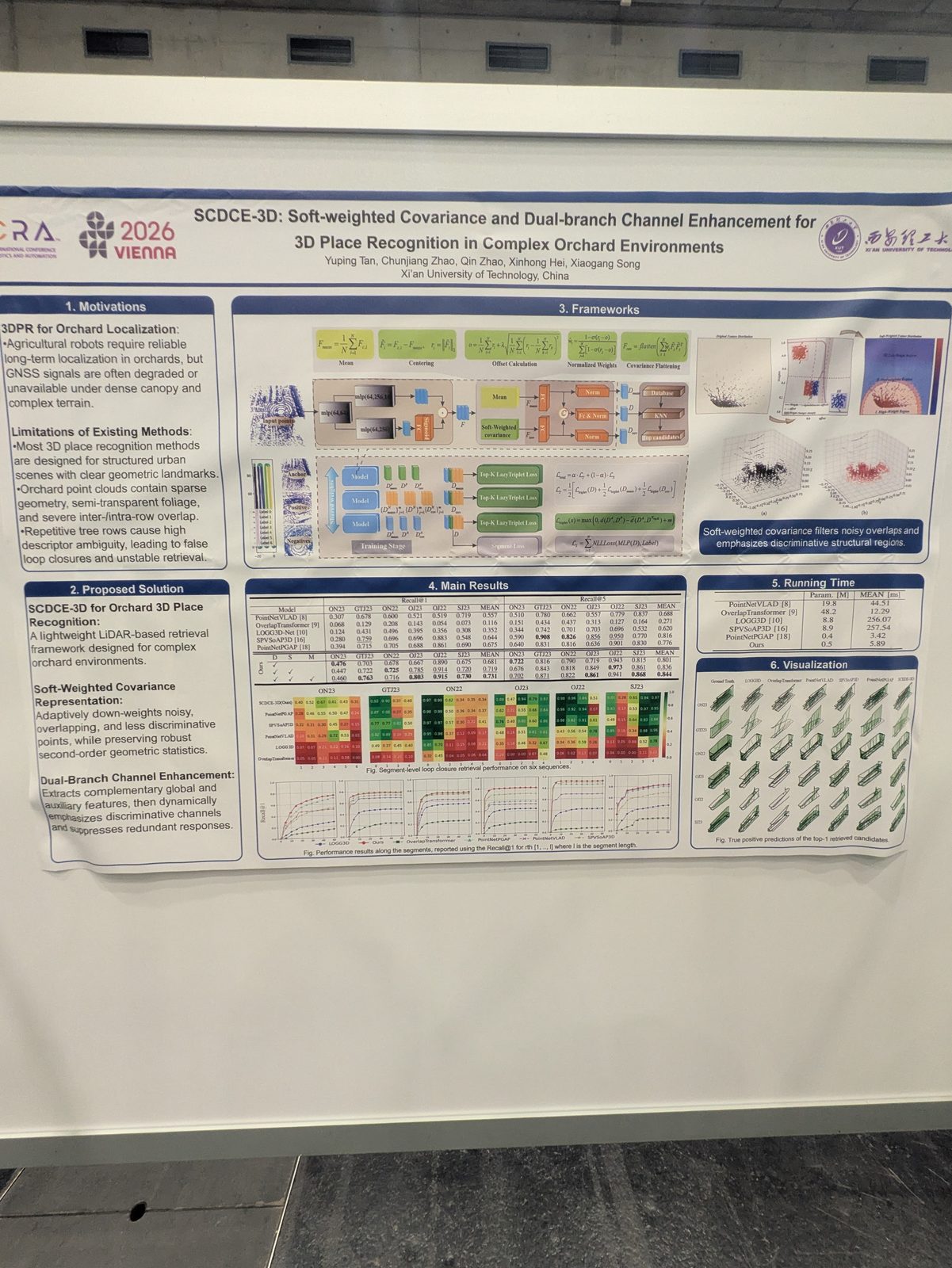
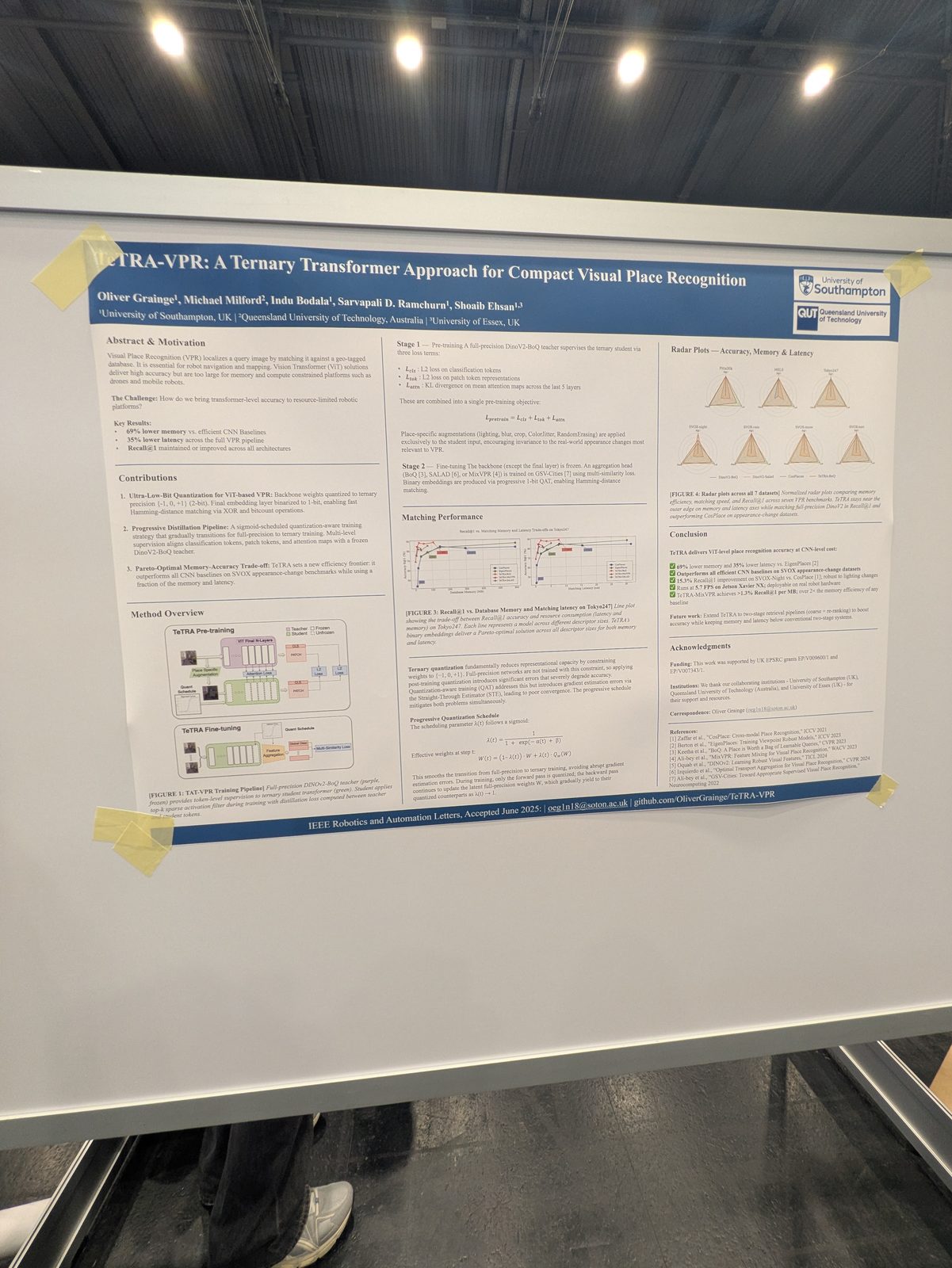
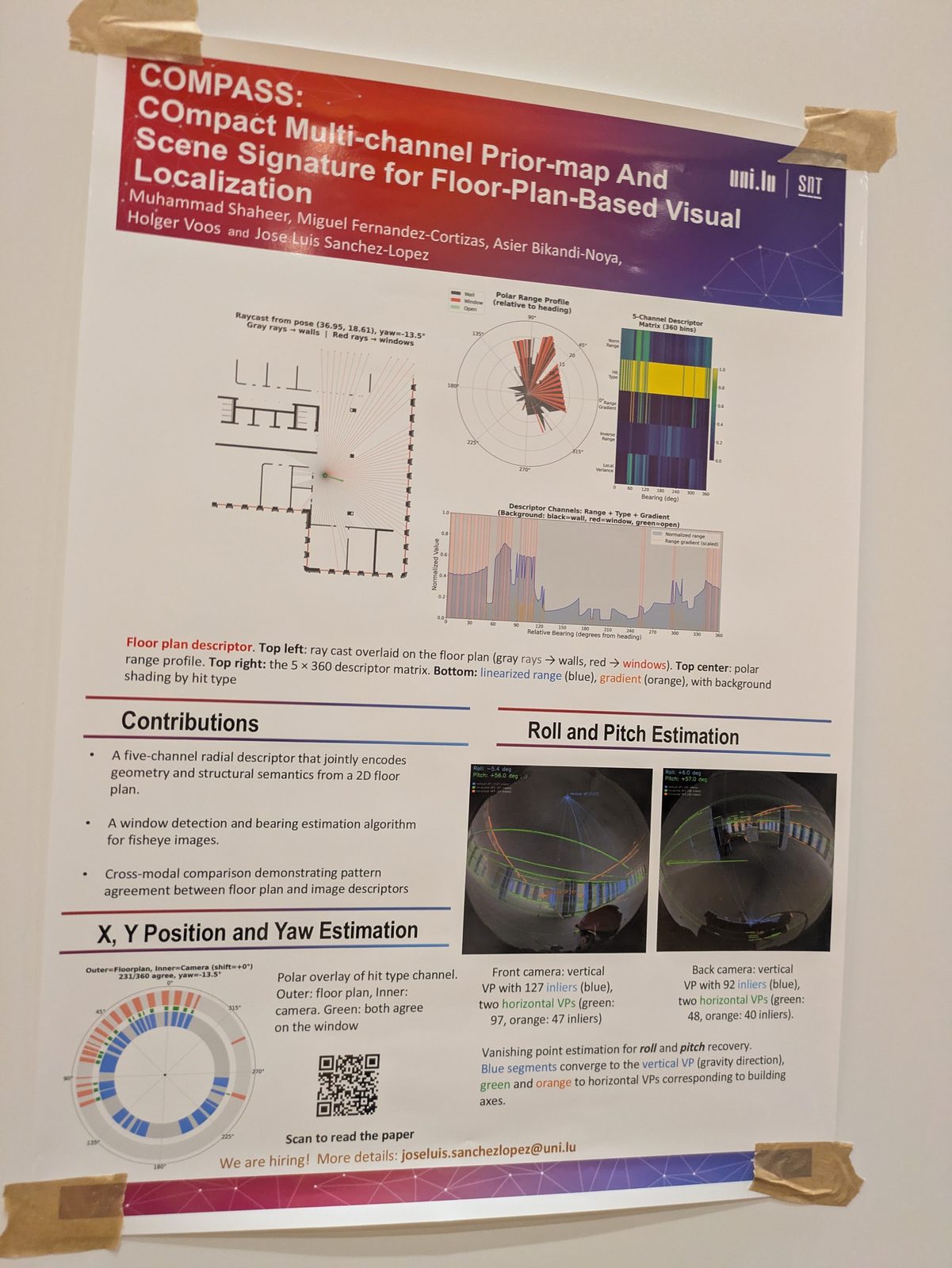


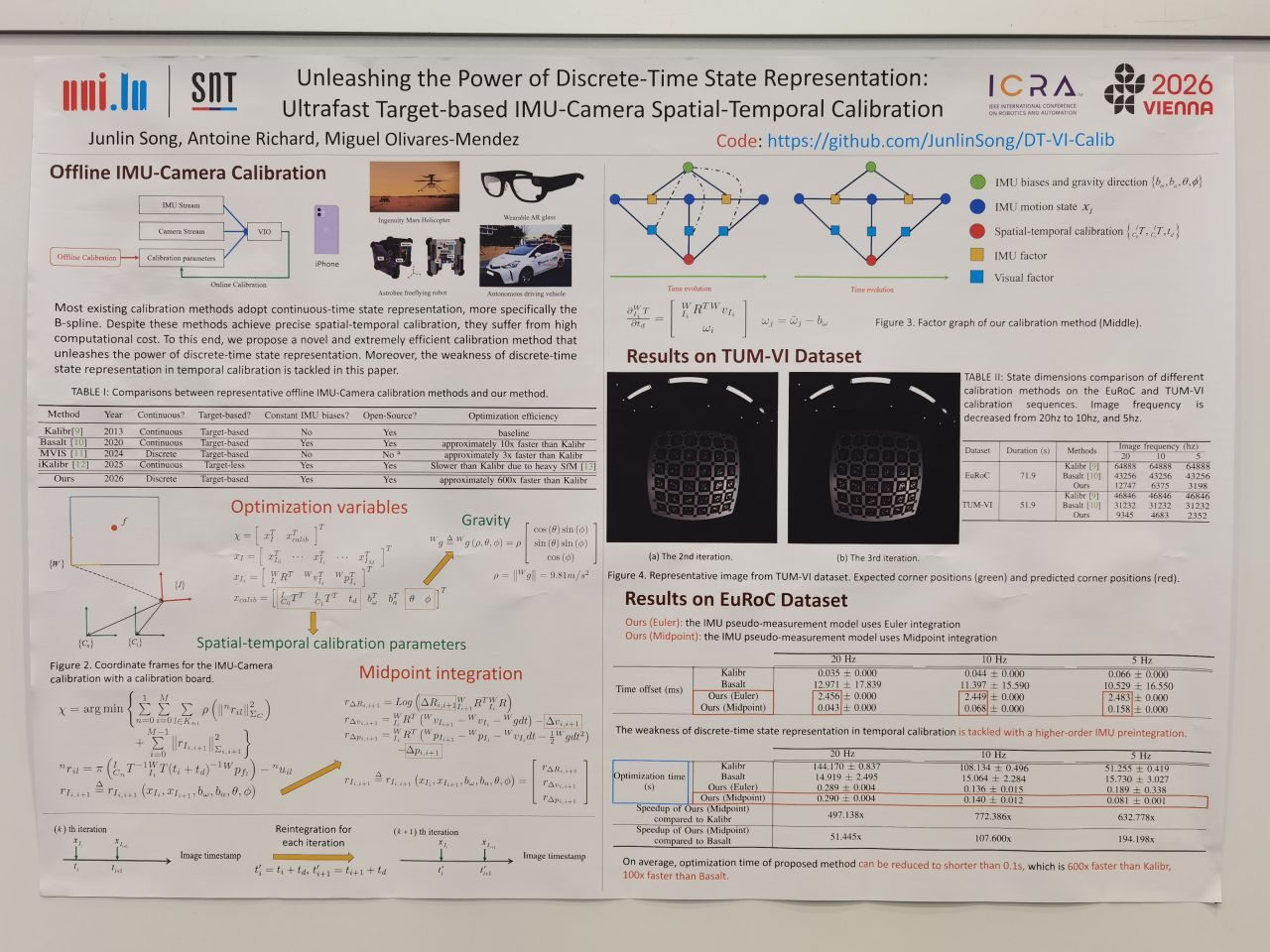
State estimation, calibration & optimization

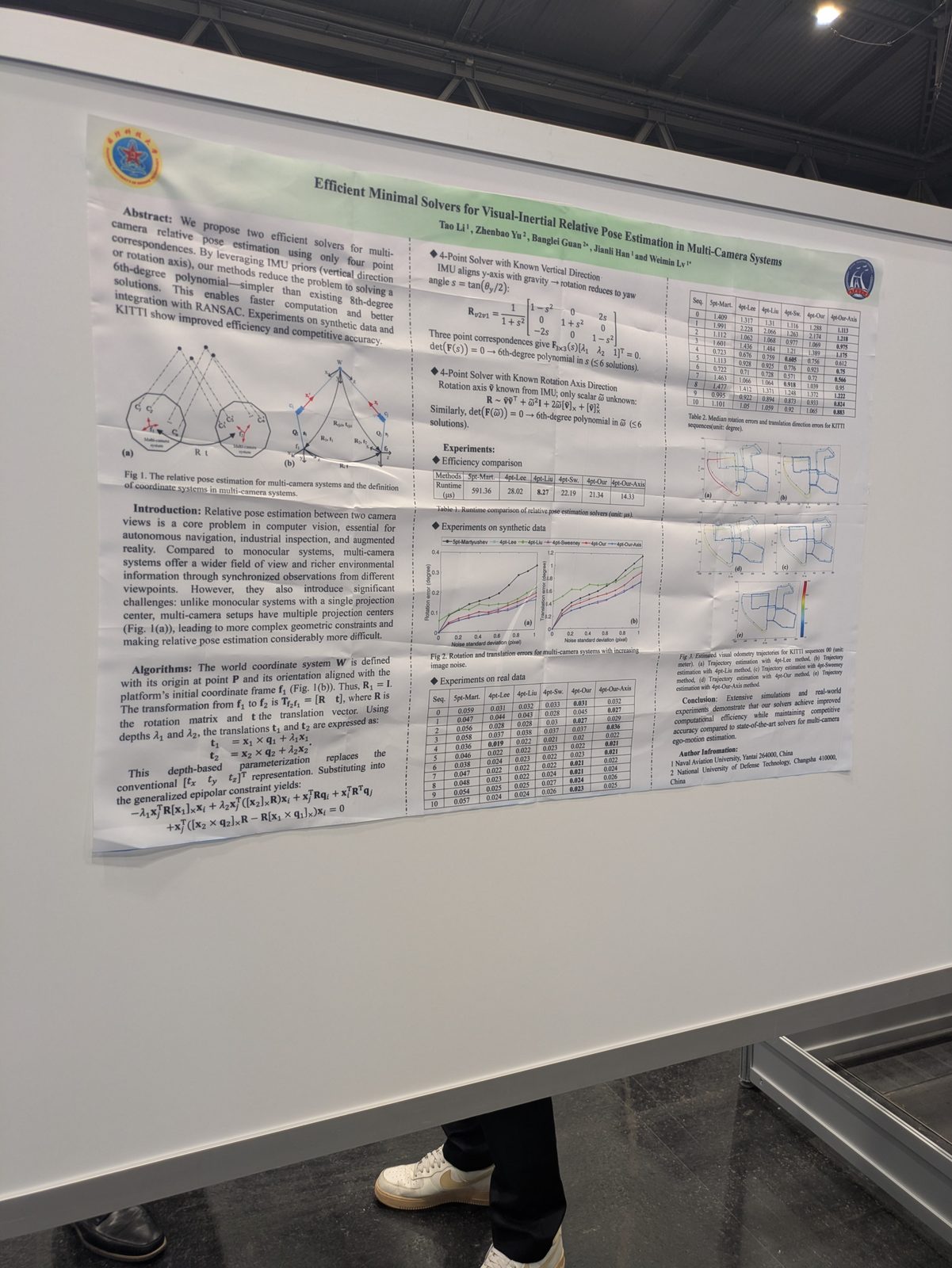
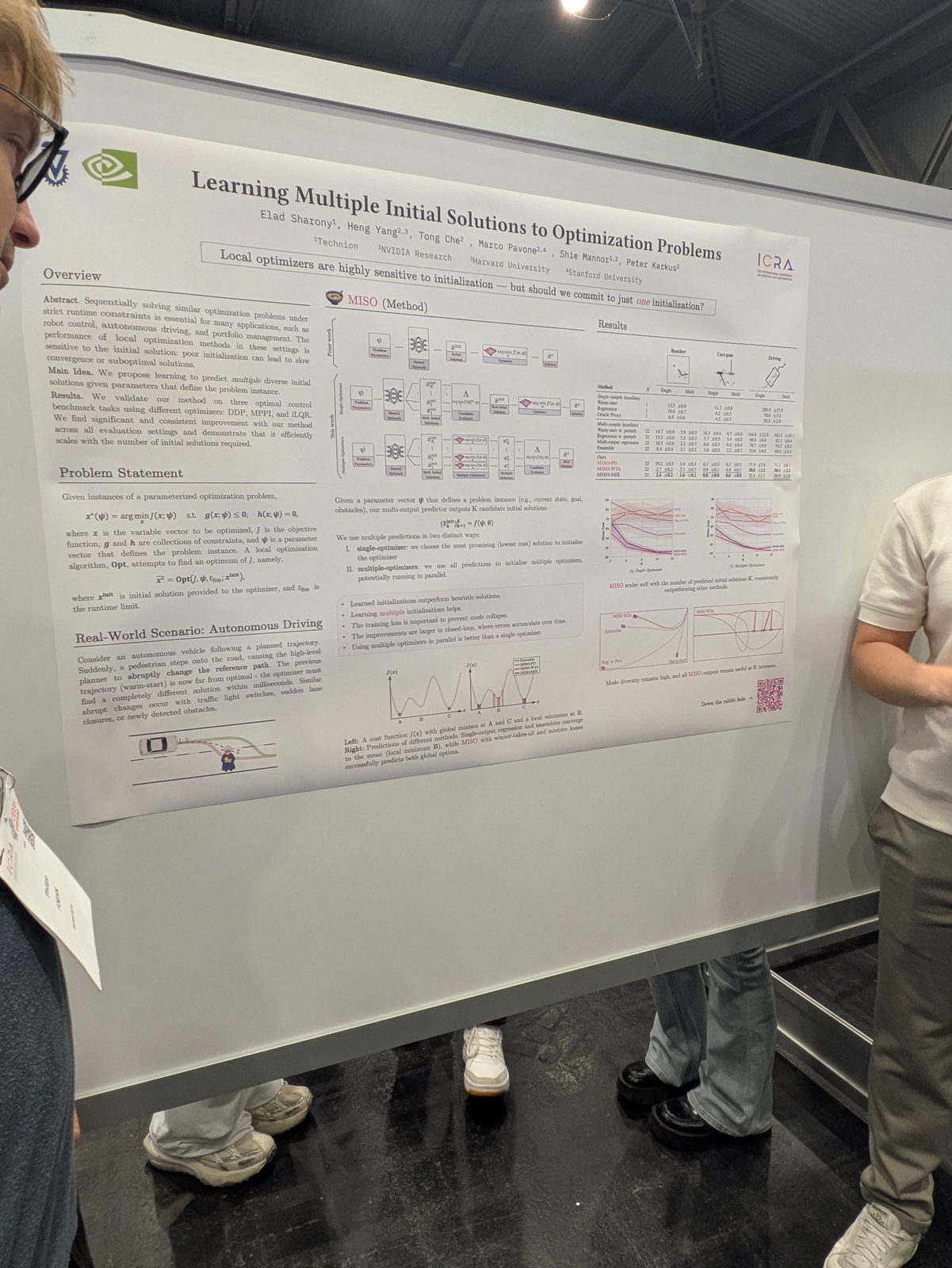
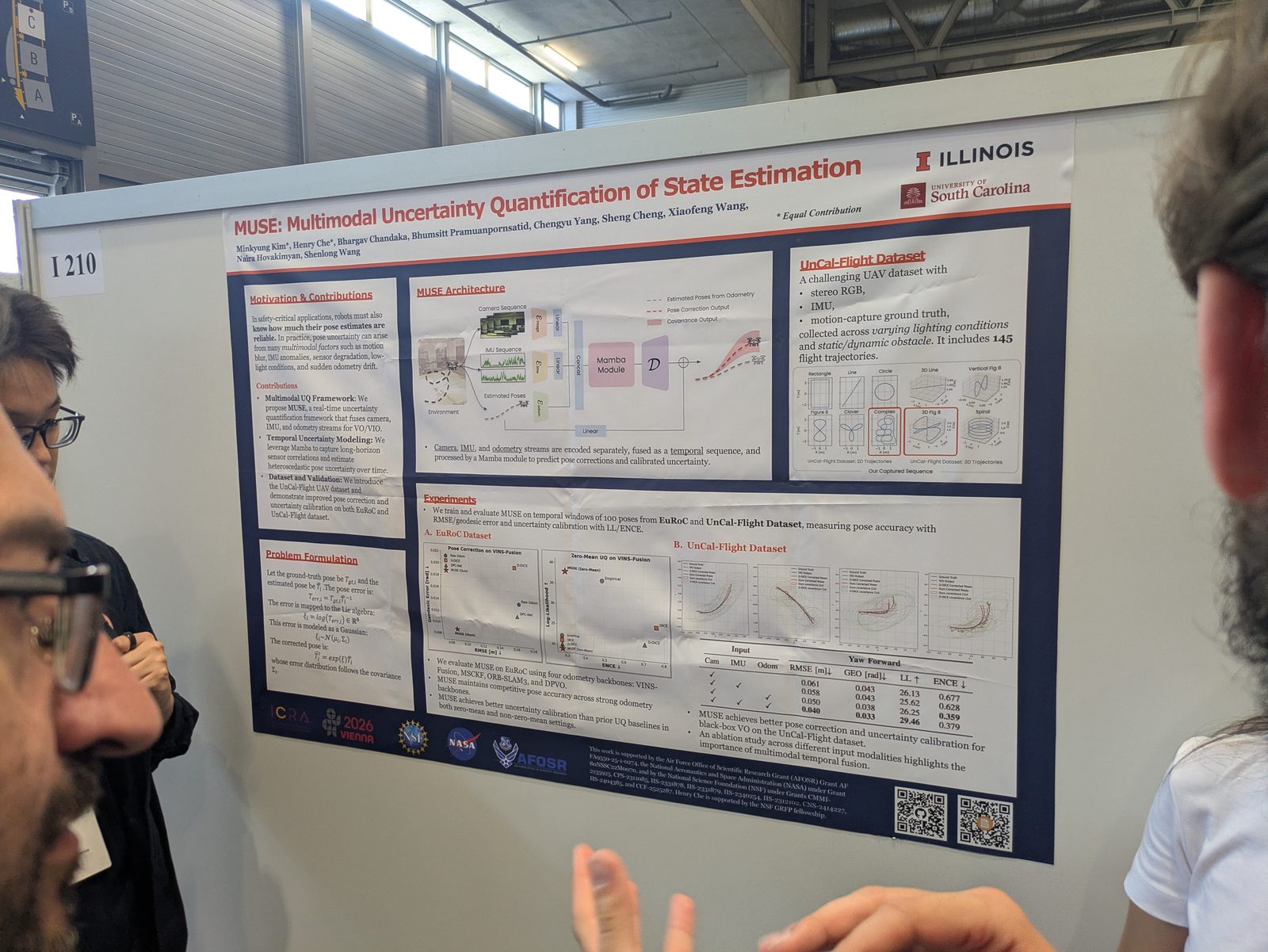
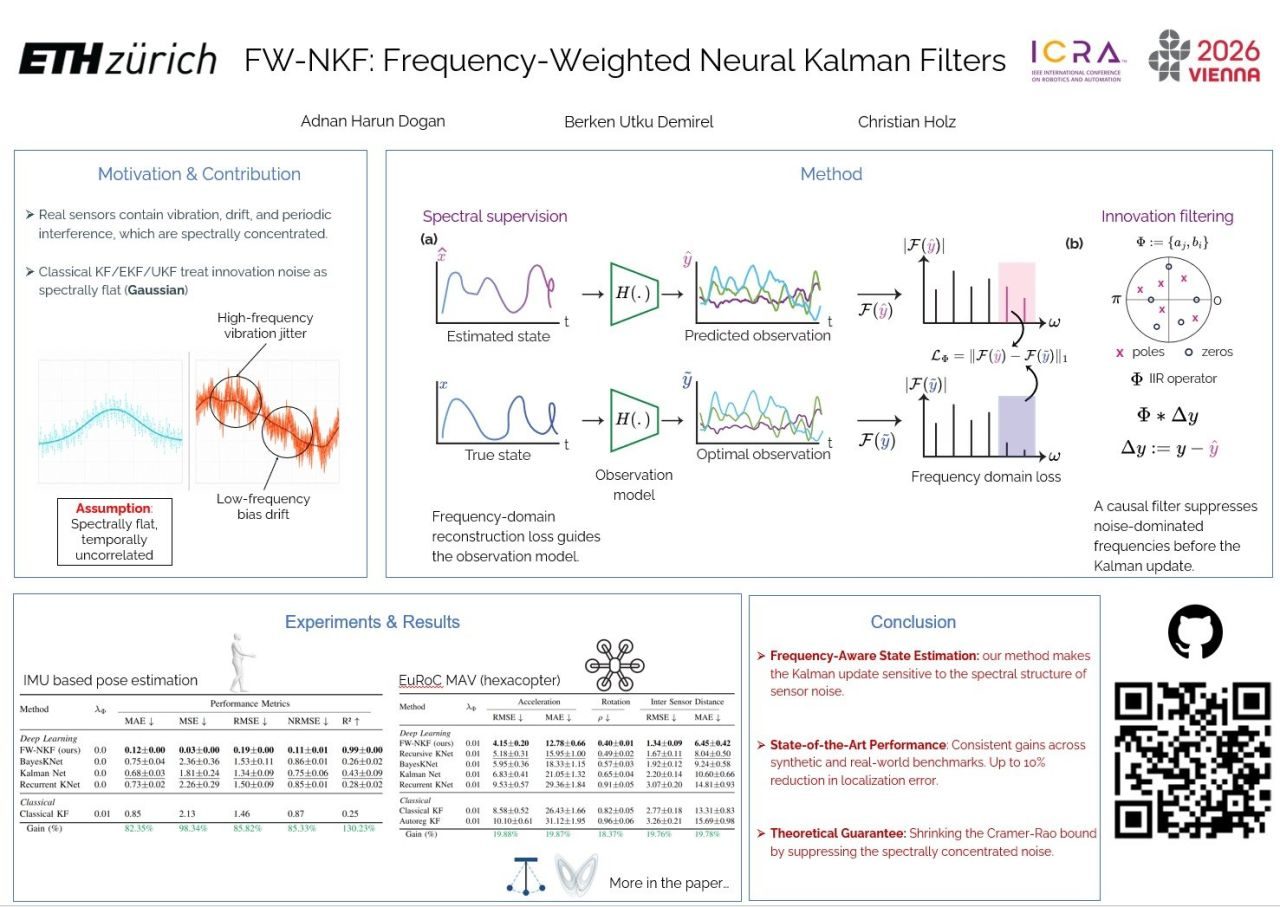
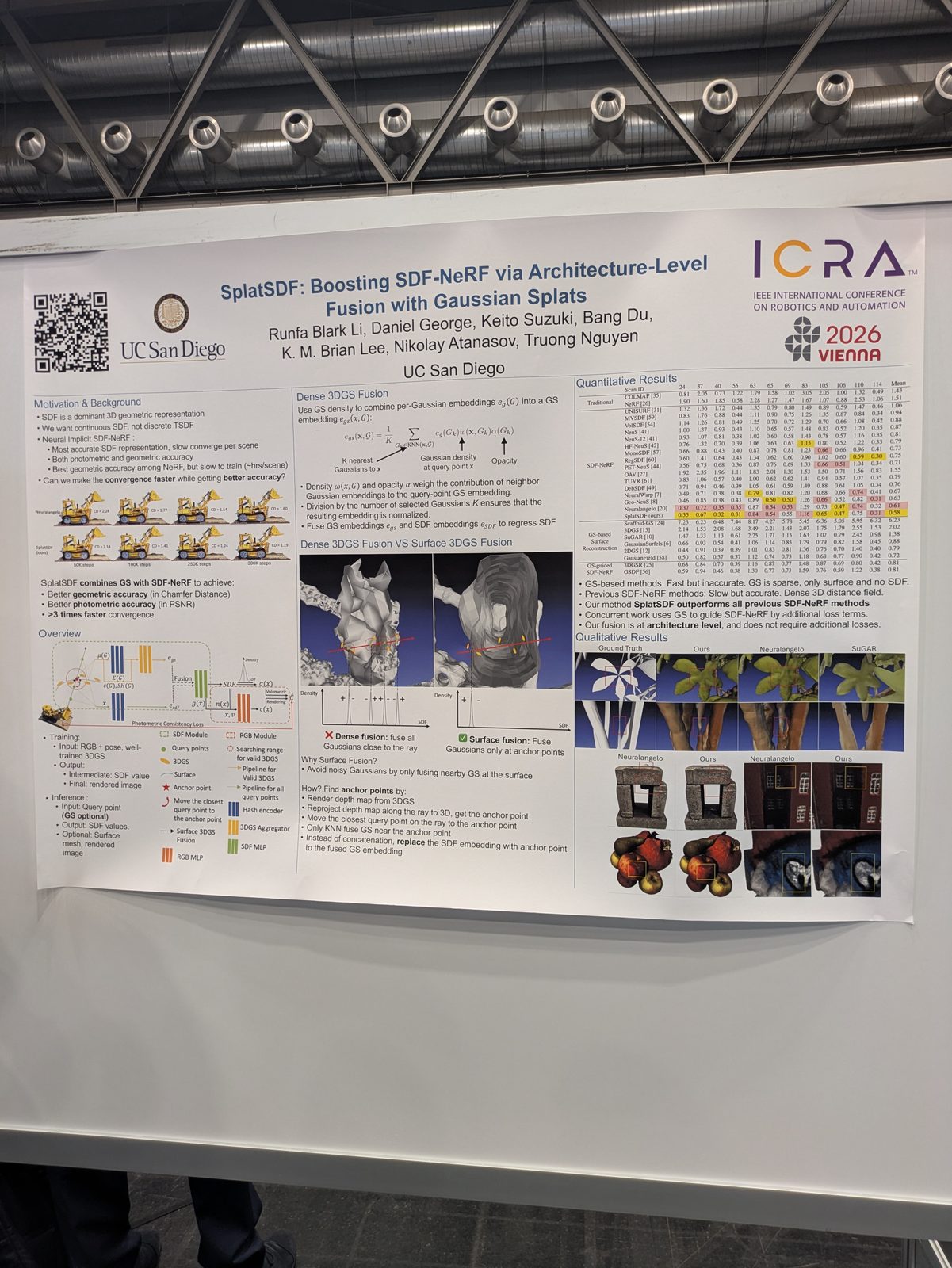
3D reconstruction & Gaussian splatting
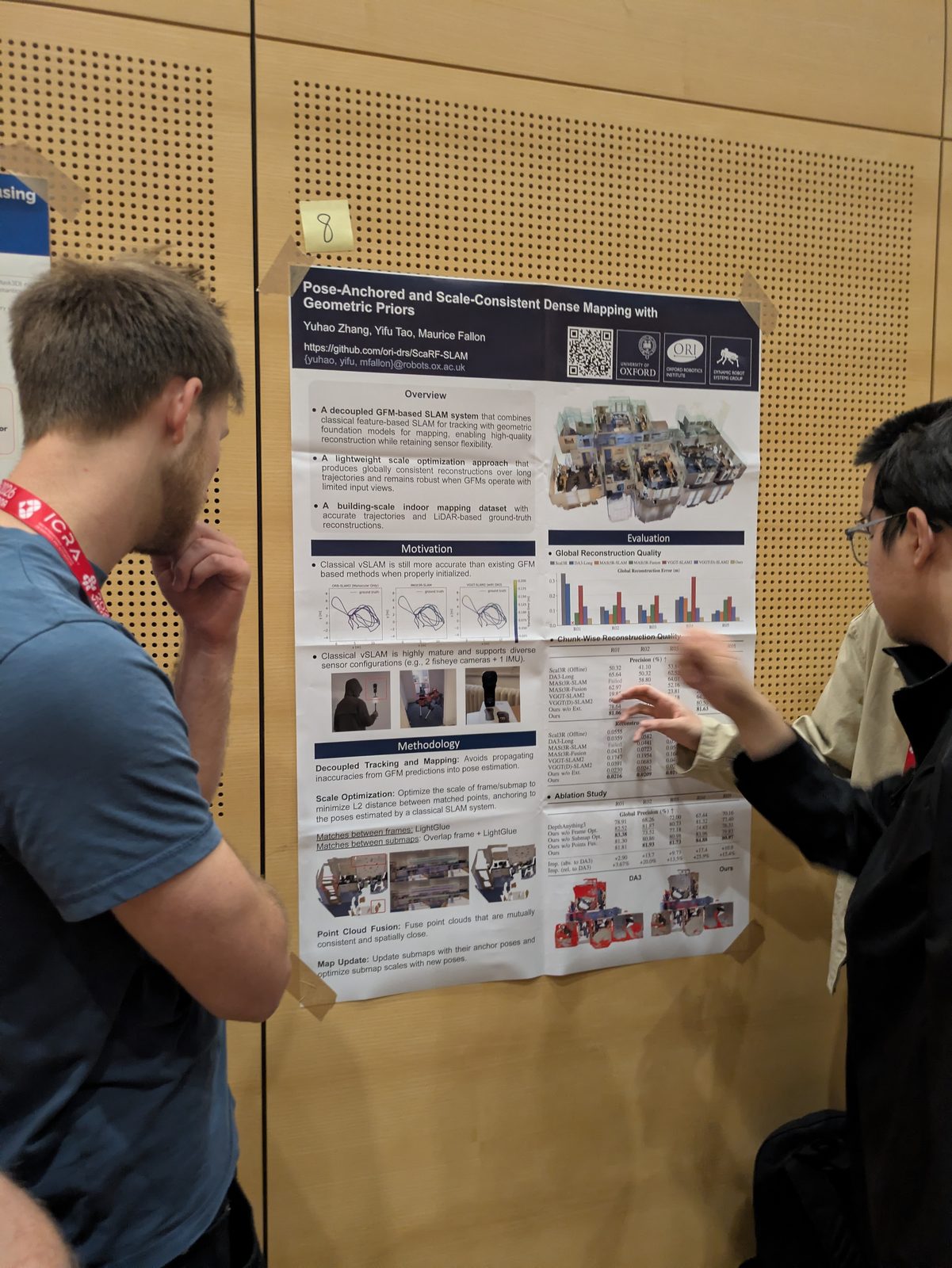


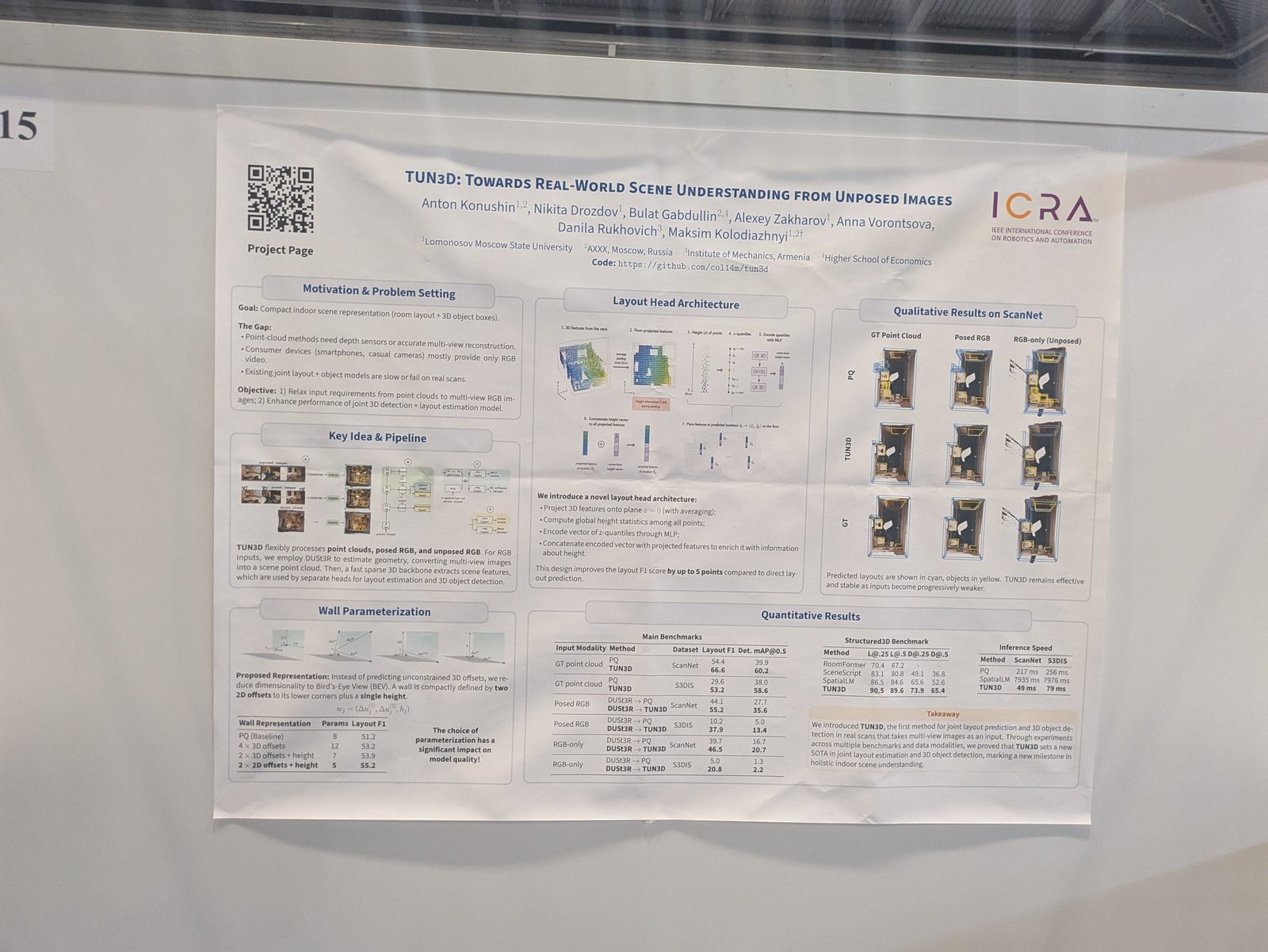
Mapping & scene graphs

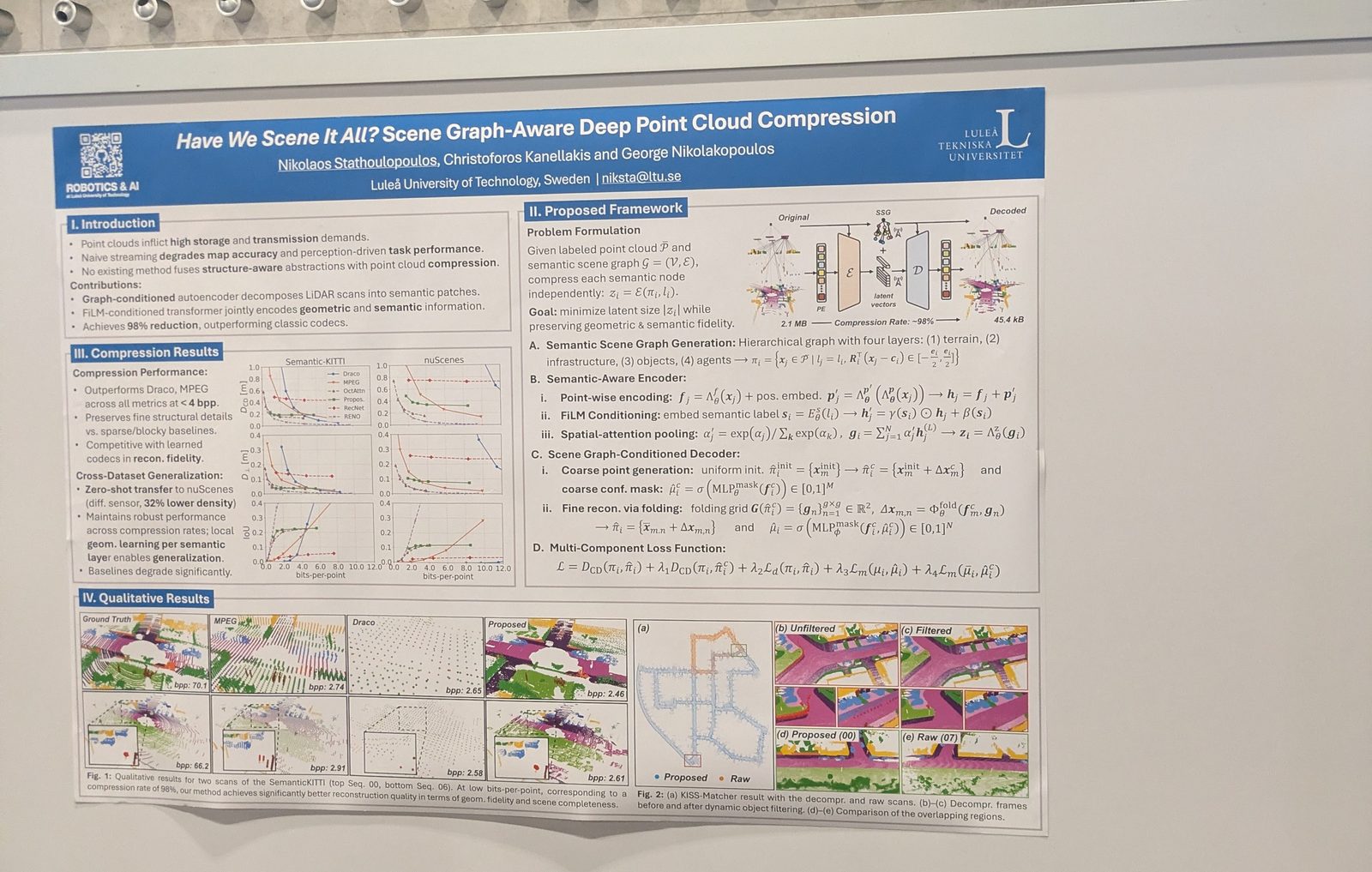



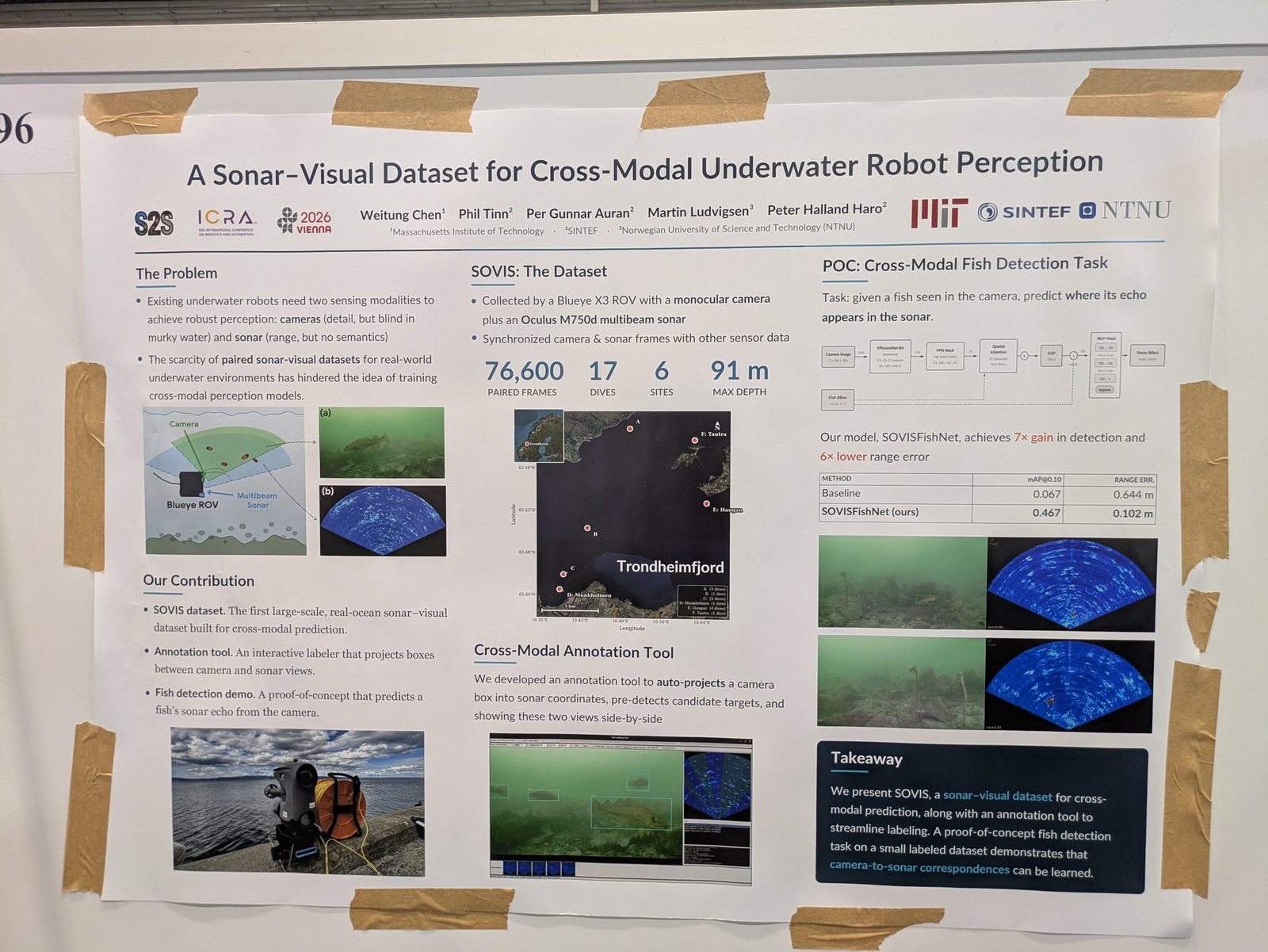
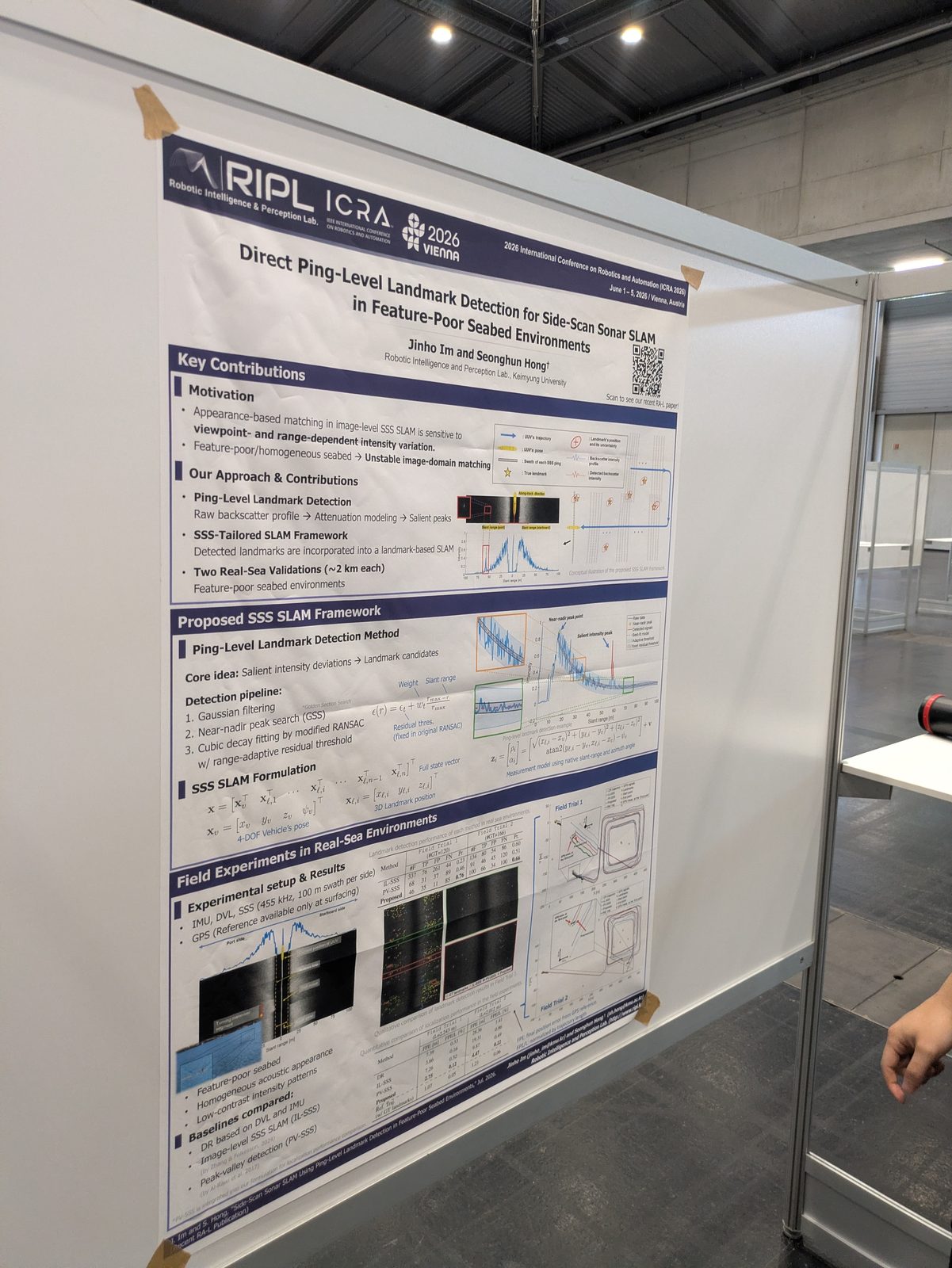
Marine & underwater


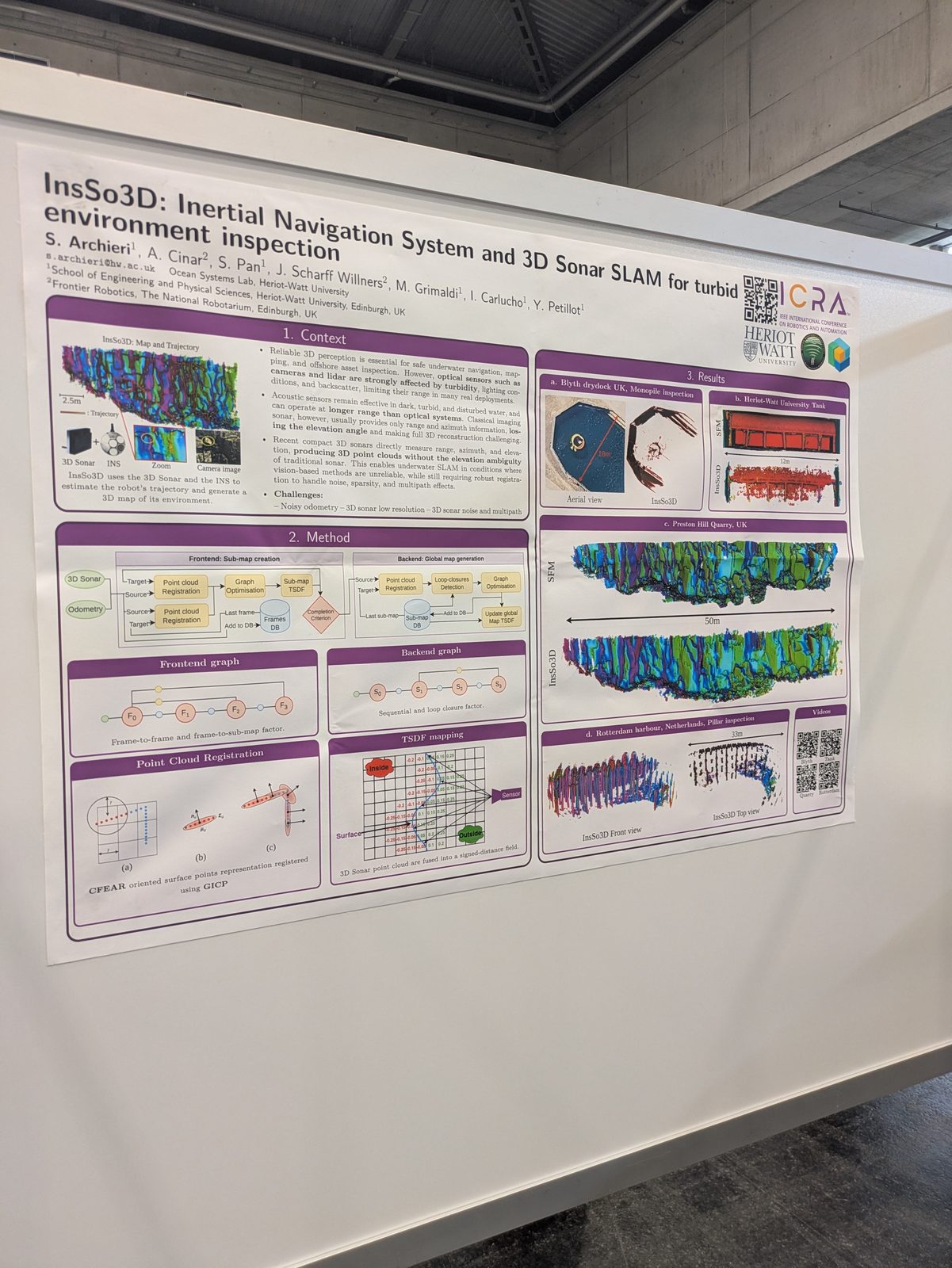
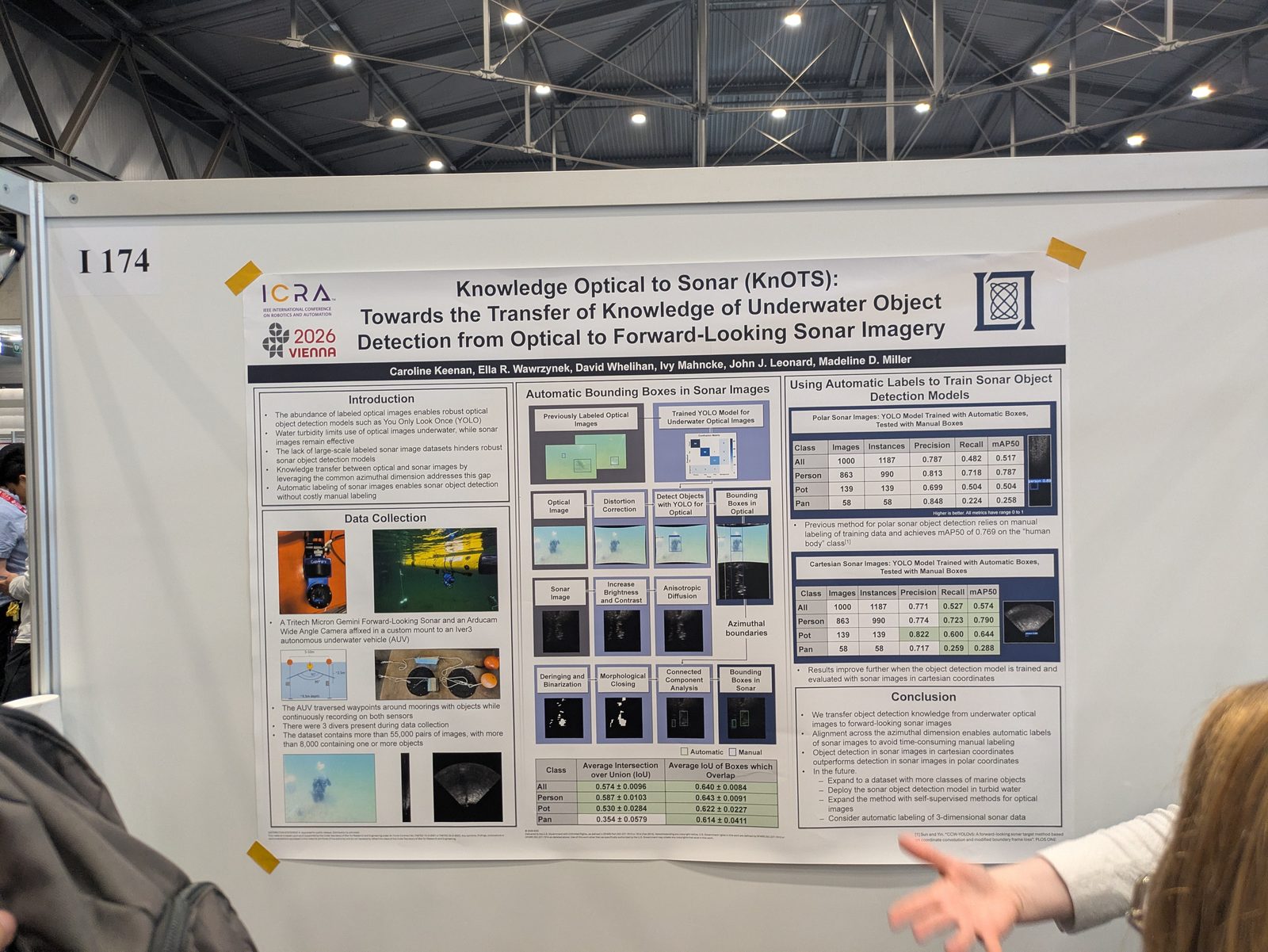
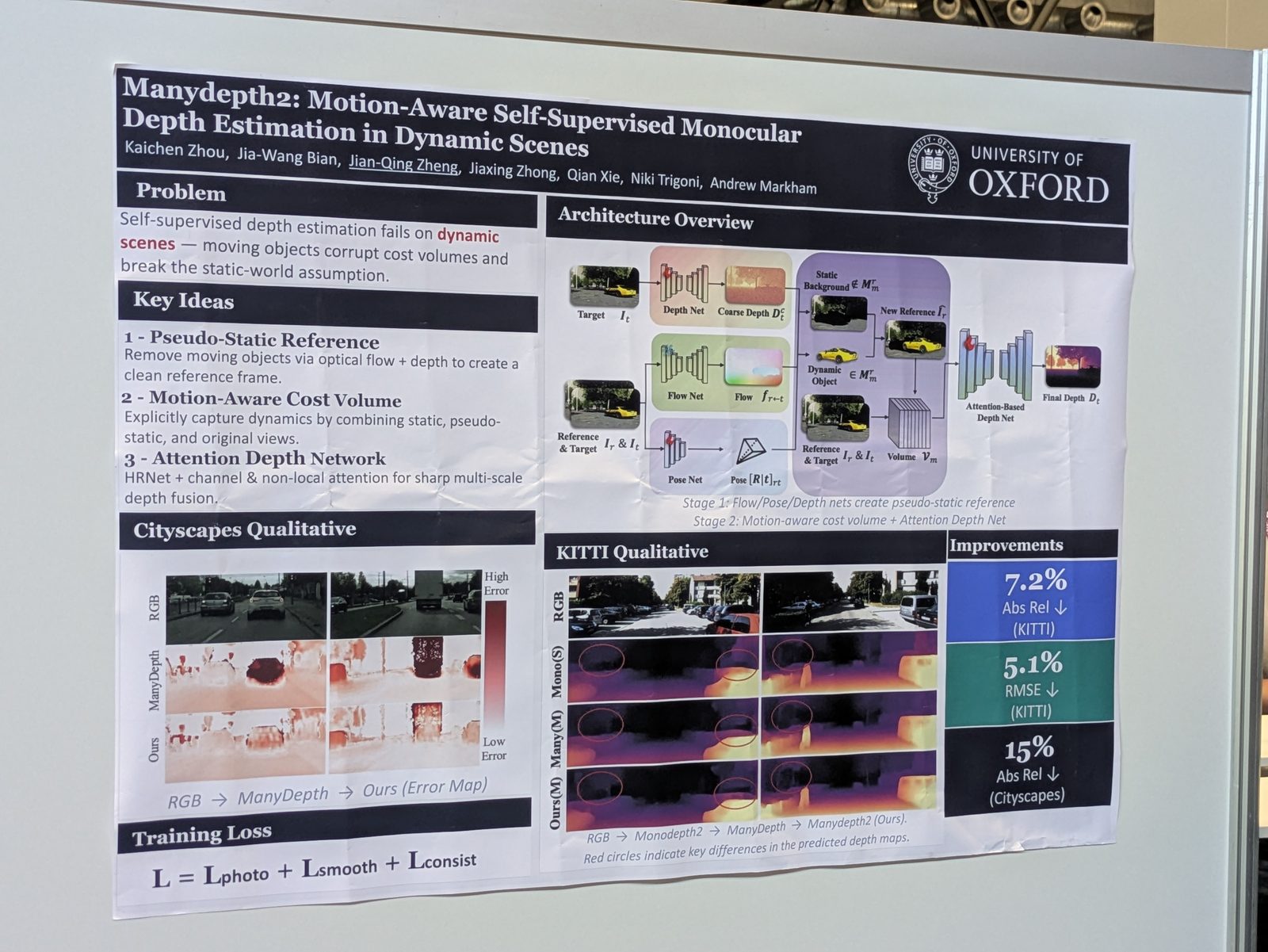
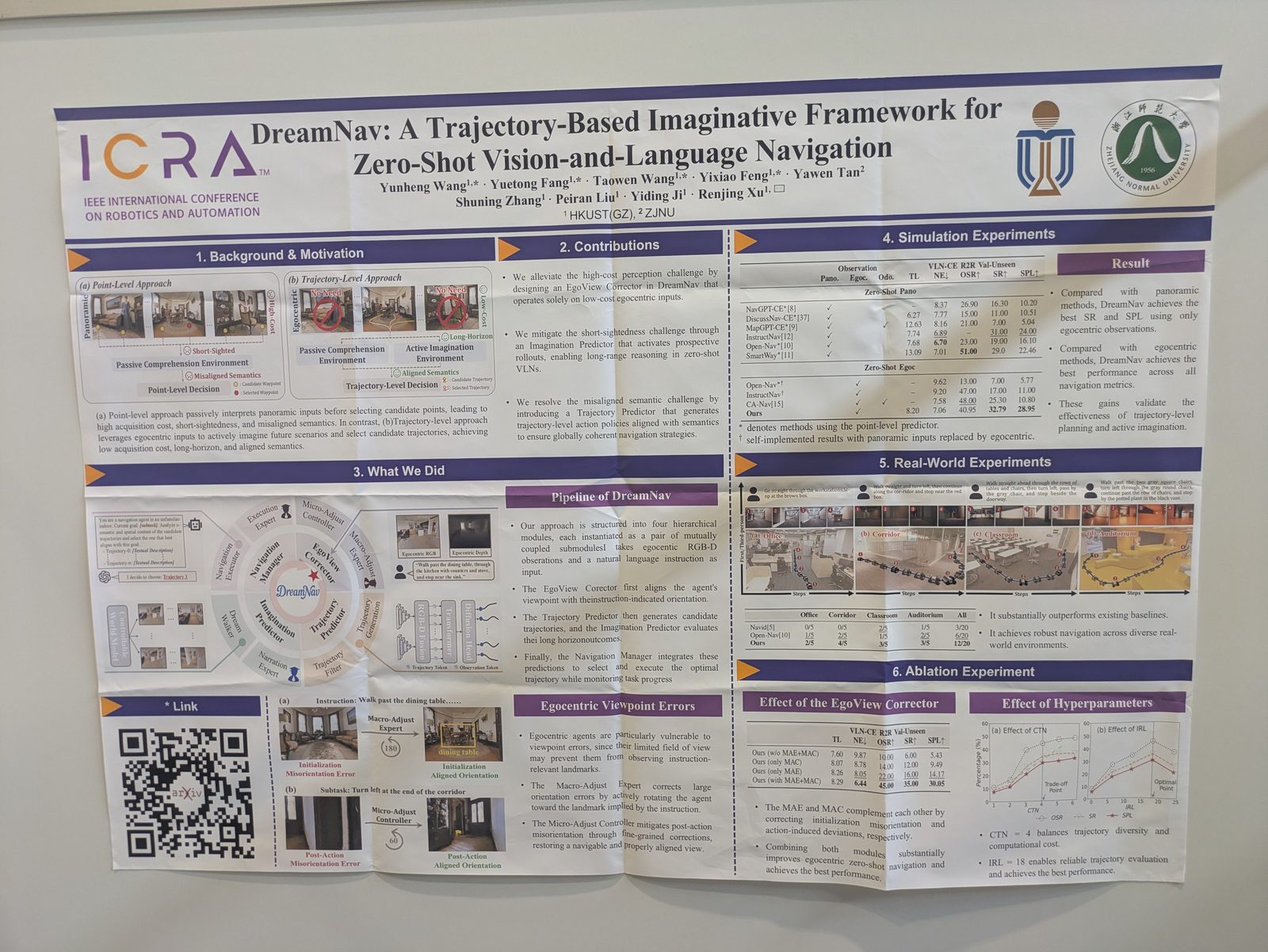
Autonomous driving
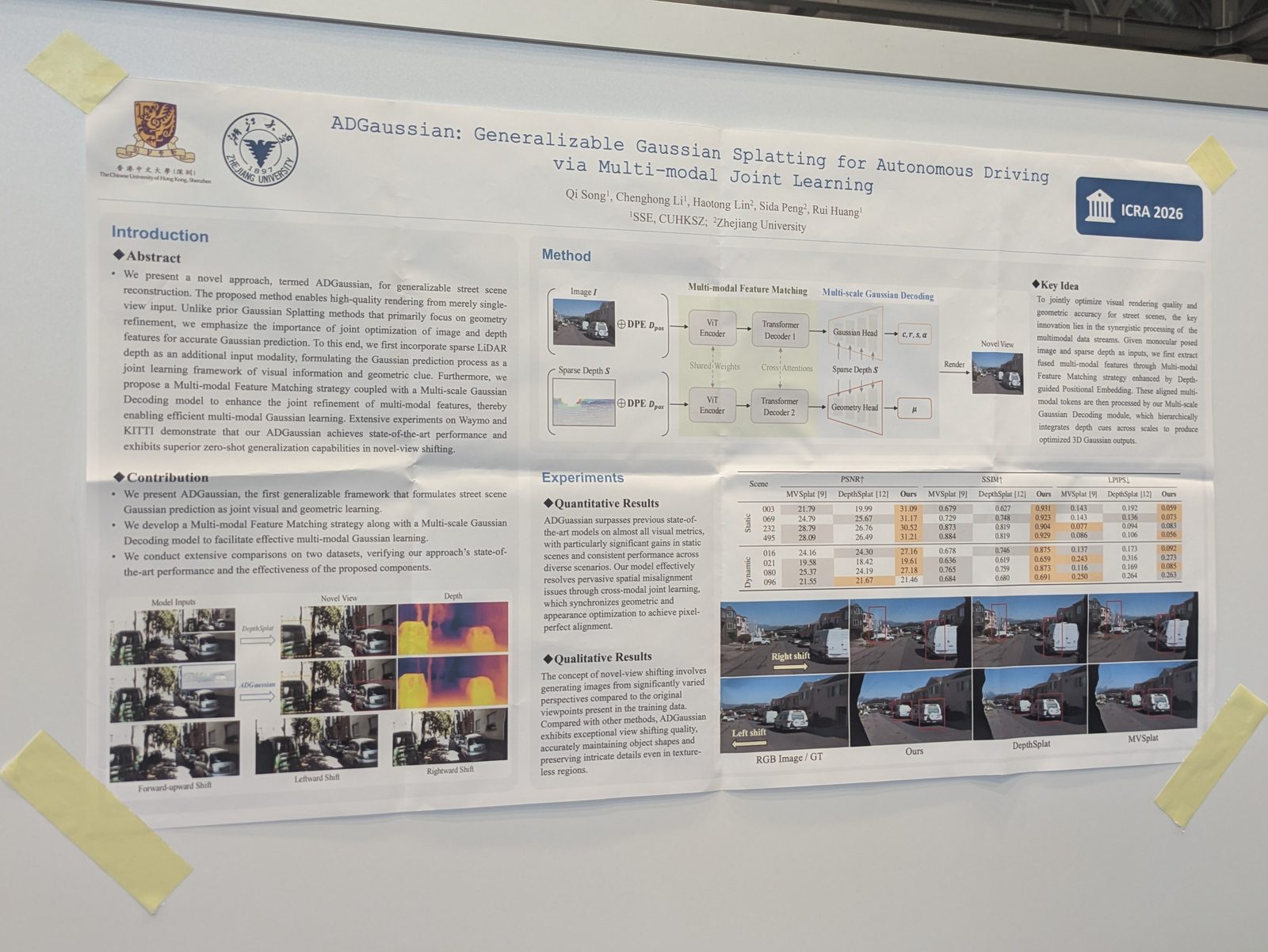
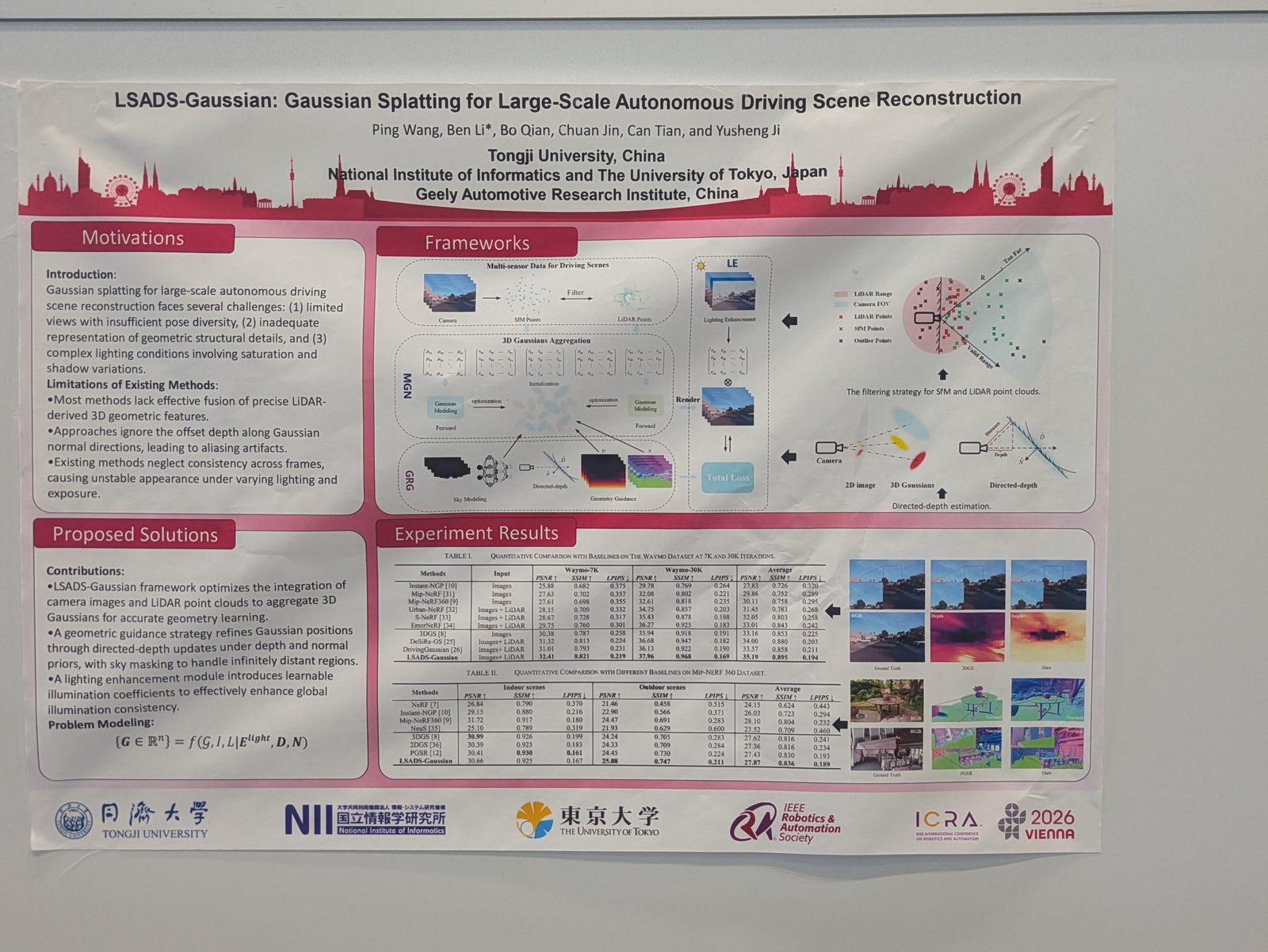

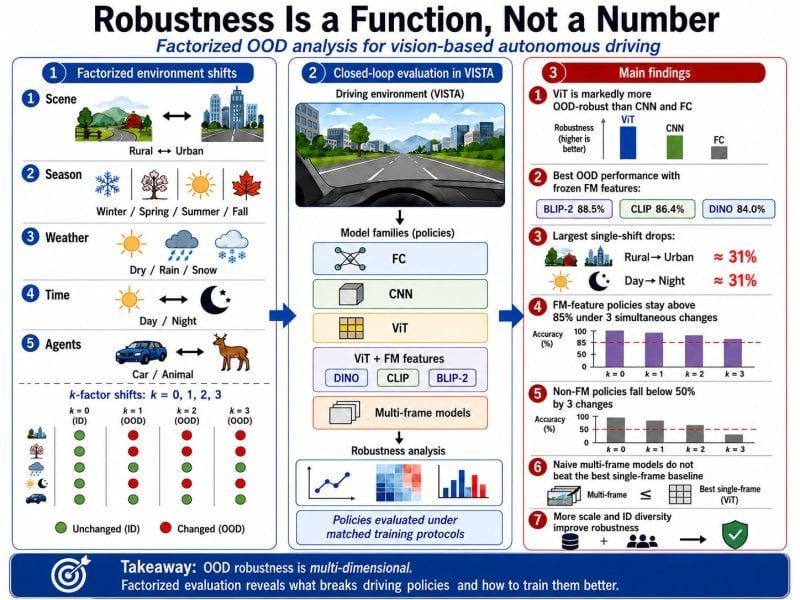
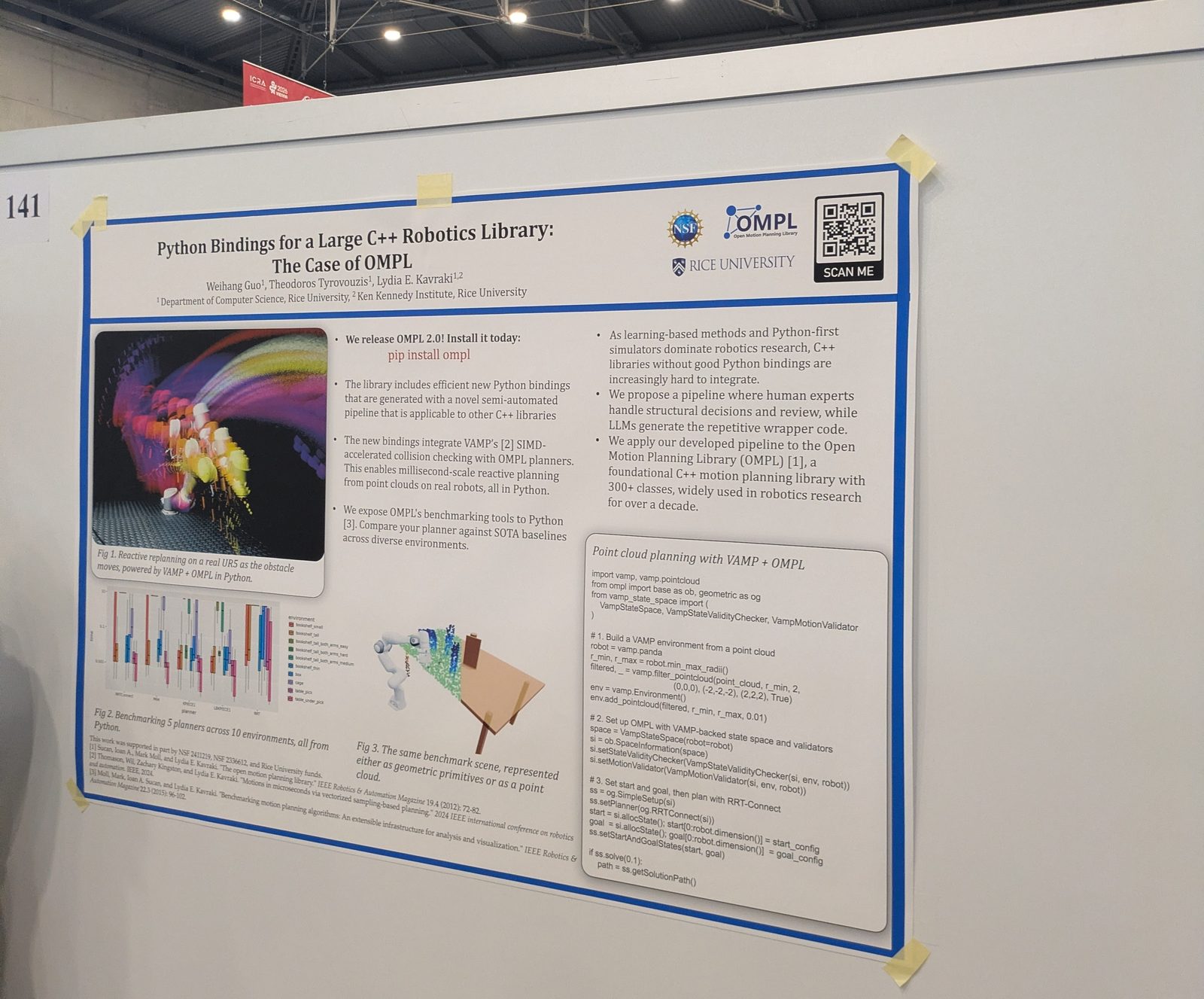
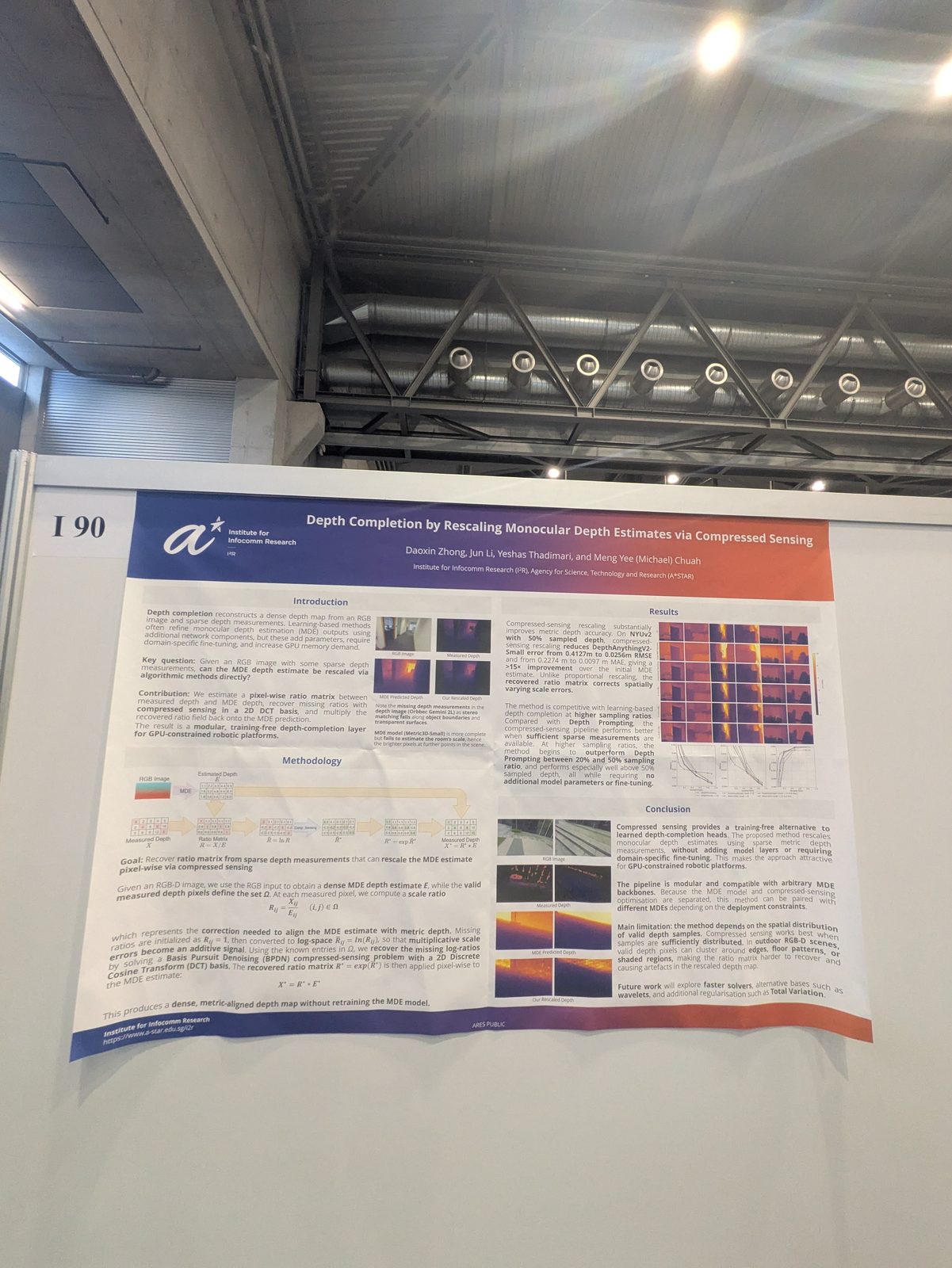
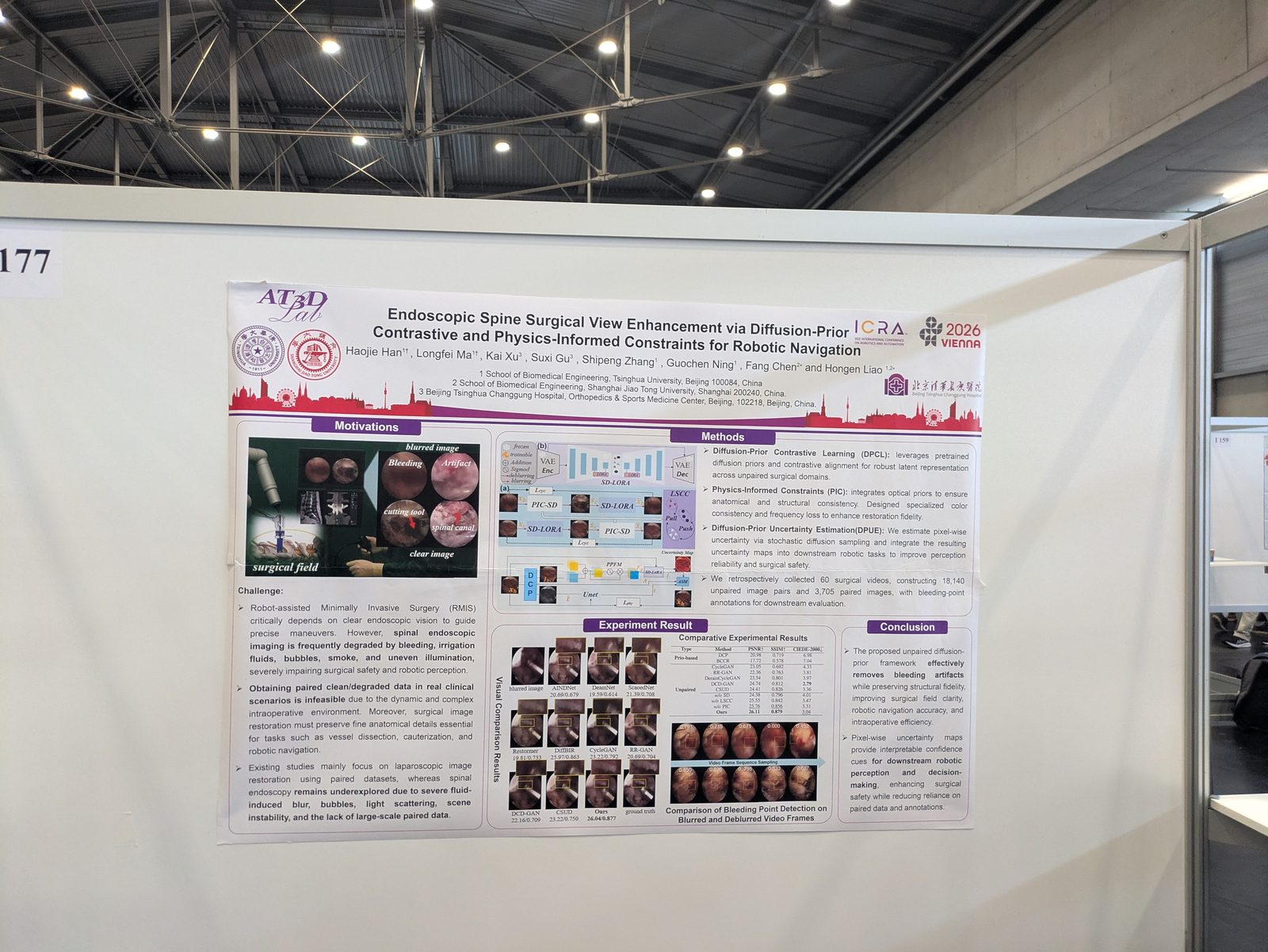
Other topics



Our poster: the building blocks of learning-based monocular visual odometry for underwater environments

I presented our poster at the S2S: From Sea to Space workshop on day 1 — and it won the Best Poster Award! 🏆 A big thank you to everyone who visited, and to the organizers. It was great to share our progress on building the foundations of an AI-based monocular visual odometry system, and to exchange ideas with all of you.

S2S award winners: Yujin Park (Best Talk Award + Travel Grant) and myself (Best Poster Award).
Other links
- Reproducibility in Robotics: IEEE Young Professionals at ICRA 2026 — the session is up on YouTube.
The Good Reviewer: shaping up peer-review in the robotics community
One workshop I sadly couldn’t attend (it clashed with S2S on day 1): The Good Reviewer, on fixing the peer-review process in robotics — organized by Alejandro Fontan, Javier Civera, Tobias Fischer, Michael Milford and others. Luckily, they compiled a great list of resources on their website, so we can all become better reviewers from home:
Guides, blogs and tutorials:
- How to write a good review? — CVPR 2020 tutorial.
- Reviewing the review process — ICCV 2021 tutorial.
- Awesome resources for better reviewing of computer vision papers.
- Novelty in science: a guide for reviewers — on not confusing novelty with complexity.
- How to be a good reviewer? — CVPR 2022 reviewer tutorial.
- And how to write good reviews — LXCV @ CVPR 2021.
- Novelty is in the eye of the beholder.
- How to review a scientific paper: some guidelines — IEEE RAS Young Reviewers Program.
- Surviving the review process — IEEE Robotics & Automation Magazine.
- Reviewing a scientific paper (Stéphane Caron).
- How to review a paper (Nathan Lambert).
- Reviewing papers with ADHD (Talia Ringer).
- A quick guide to writing a solid peer review.
Official reviewer guidelines:
- RA-L information for reviewers.
- Information for ICRA reviewers.
- CVPR 2024, NeurIPS 2023 and ICML 2022 reviewer guidelines.
Ideas I left with
Notes-to-self scribbled in the margins during the week:
- Rather than focusing so much on monocular vision: 3D scene graphs underwater?
- Try VGGT for depth.
This post is a work in progress…
Enjoy Reading This Article?
Here are some more articles you might like to read next:
- ICRA 2026: an interactive topic map
- My ROSCON 2024 digest - Days 2 and 3
- My ROSCON 2024 digest - Day 1
- Setting a Jetson AGX Orin for robotics development (III) - event-based SLAM
- Setting a Jetson AGX Orin for robotics development (II) - Inivation's event camera
- Setting a Jetson AGX Orin for robotics development (I) - building the basis
- My ICRA 2023 digest
- Surveying SLAM algorithms with ROS (I) - Installation
- creating ROS metapackages
- LateX table tricks for no more table flips (╯°□°)╯︵ ┻━┻