To enhance or not to enhance? Computer Vision in challenging imaging conditions

The question that gives title to this post is one that I’ve been asking myself a lot recently. But before I get into it, let me give you some context on how I got here:
My first -serious- computer vision project was a Visual Odometry algorithm for a drone camera. It was my Bachelor Thesis, which means that I implemented the whole thing (looking at David Scaramuzza and Andrew Zisserman works) from scratch and in the “traditional” way. Surely that was reinventing the wheel, and there were more modern techniques to solve the problem, but the whole point was to learn how it works.
After that I started working with an underwater robot in the European project STAMS, which made me find out that: 1. there’s very little work in underwater computer vision, and 2. there’s a very good reason for that: the imaging conditions make it very difficult to extract any kind of information from the pictures.

For my Master Thesis I decided then to implement a Visual Odometry algorithm again… But let’s make it underwater now! However, I found out that I could not extract information the traditional way (i.e., keypoints) with the picture as it is. So, the next step I took was to process the image in order to improve the saliency of those keypoints, and remove all the noise that came from the underwater image formation.
Again, I avoided the use of Deep Learning, because I wanted to get to know very well why and how was this challenging image formation occurring, and how to solve it. If you’re interested in my findings, you can read my journal article published in Sensors. You’ll find that I did a simulation of this imaging conditions too. That was because, now that I know how this happens, why not simulating it?
Anyway, after all this research, and taking now into consideration Deep Learning techniques, a new question arises in my head: What’s better now, processing the image first and then extracting the information (both with DL algorithms), or just directly training a Deep Learning algorithm to extract the information from a raw underwater picture?
What my intuition first told me is that deep learning algorithms such as image classification, if trained with underwater images, would perform the required enhancement (or preprocessing in general) themselves. Kind of like an underwater black box for image classification. However, it turns out that doing that preprocessing separately improves the performance of the classification algorithm. This makes me think of some advantages that doing those two steps separately could imply:
-
More modular algorithms: that means, if you want to take only the enhancement part, or just the image classification part, you can separate them easily as they don’t directly depend on each other. That is, it’s easier to recycle the code. Maybe this advantage is not such a big deal for developers who have high computing resources, as they can just quickly train a new deep net. But for you, it might be something to take into consideration.
-
Recycle code: maybe you have a better (or specific to your use-case) database for image enhancement. Or maybe you don’t have an image enhancement database, but want to train your neural net in your specific object-scene-whatever recognition database. If you’re focused in a very specific part of your algorithm, it seems like a good idea to rely in a previous work from someone more experienced than you (or with better data than yours) to do that other part. That third-party software will probably work better than yours… and if you save that time, you’ll be able to focus better in your field of expertise!
I found a couple of works that perform an image enhancement and afterwards use object detection as a metric of such enhancement:
The work proposed by Li Yujie et al. performs a de-scattering and color correction based on a model on the scattering and the color distortion. They don’t use deep learning for the enhancement process itself, but they have tested their preprocessed image altogether with a classification algorithm, to conclude that the performance of the classification had improved slightly. However, when performing an image enhancement it should be taken into consideration the different distortions that the image could suffer. One of the most popular classifications of the these distortions is listed in the Jerlov water types. Pritish Uplavikar et al. use a encoder-decoder network to disentangle the unwanted nuisances corresponding to the Jerlov water types. They used a synthesized dataset to train it. When performing a YOLO object detection over the synthetic images, the object detection is better. However, they say the improvement is not so clear over a this real dataset. They didn’t give any conclusion on why this might be. I think it maybe is because the object detection itself over underwater images isn’t as good, since there isn’t much training data on objects in underwater contexts. They use YOLO, which is trained with the COCO dataset, which, for example, has 6808 images of persons…but probably very few of them, if any, are scuba diving.
 Left: person in the COCO dataset. Right: person in the UIEB dataset.
Left: person in the COCO dataset. Right: person in the UIEB dataset.
Anyhow, I don’t really reach any conclusion with this. So let’s reach our own conclusions! I want to do a comparative between the two approaches, with and without a prior image enhancement, and see which performs better for object detection. I will be using State of the Art algorithms for such comparative. But first of all, let’s think about which metrics we could use:
Metrics for object detection
Intersection Over Union
Intersection Over Union (IOU) evaluates the overlap between two bounding boxes, that is, between the ground truth (Bgt) and the predicted (Bp) bounding boxes. It basically divides the area of the overlapping between the area of the union, i.e.:
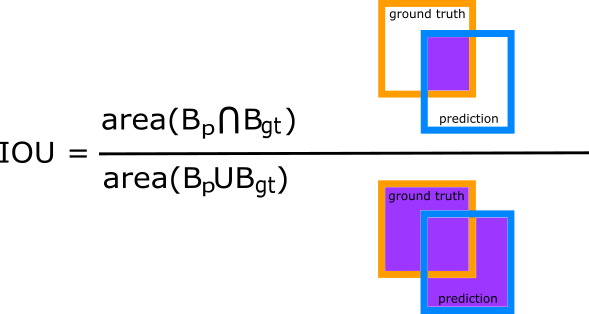
According to the returned value, we could have:
- True positive (TP): IOU > threshold. There is a ground truth object and we fairly detected it.
- False negative (FP): a ground truth object not detected.
- False positive (FN): IOU < threshold. The object was detected, but missclassified.
The value of the threshold depends on the metric. MS COCO and PASCAL VOC use an IOU of 0.5, the minimum threshold, but also 0.75 or 0.95 are often used.
Precision and recall
These two are well known Machine Learning concepts.
Precision measures the percentage of correct positive predictions. It is the answer to the question: “ of all the positive predictions, how many are actually positive?”. It is useful when we want our model to only identify relevant objects.

Recall is the percentage of true positives among all ground truths. It is useful when we want to find all the relevant objects.

From these two values we can obtain the PrecisionxRecall curve. There is one curve for each object class. If the prediction stays high as the recall increases, we can consider that we have a good detector.
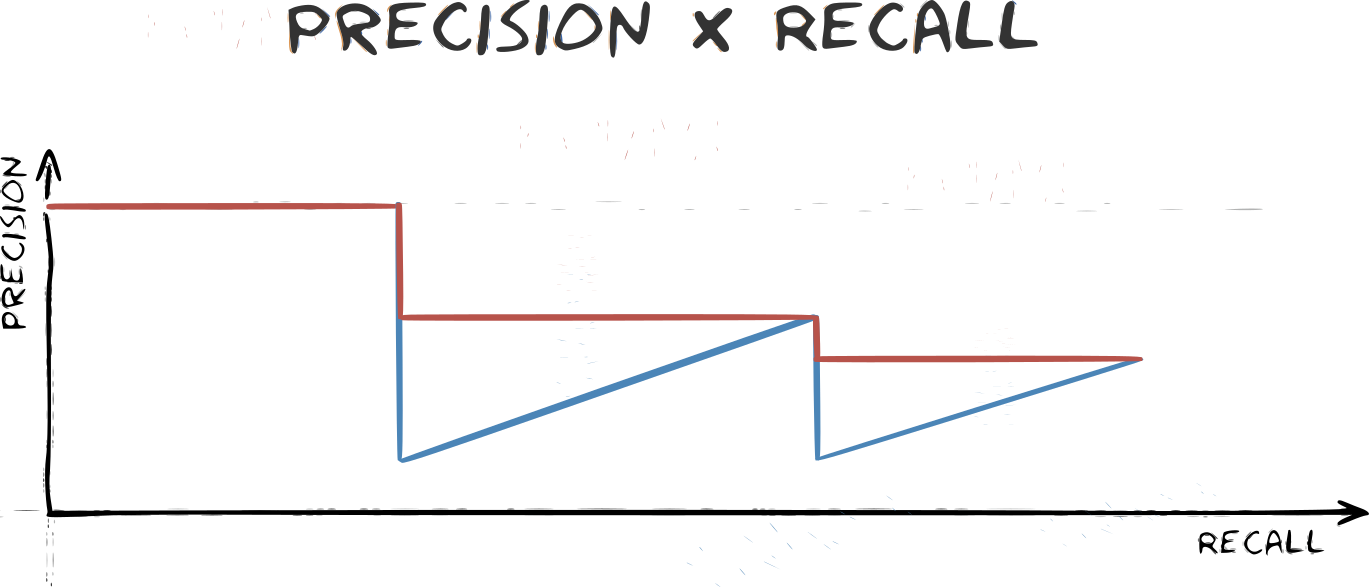
Average precision
This concept is considered in the PASCAL VOC project. Here we consider any IOU higher than 0.5 as a true positive. After that, we obtain the Precision vs. Recall curve and obtain the Average Precision (AP) as the area under the curve. It is called “Average precision” because in order to simplify the calculation, the precision is averaged across all the recall values.
-under construction-
