My ICRA 2023 digest

Mucho texto: Table of contents
Day 1. Workshops and Tutorials
W.1. Distributed graphs workshop

The chair for this workshop was Andrew Davison, who did a very short but interesting presentation as introduction to the workshop. He definitely left me with the wish of listening more from him, but two things he mentioned particularly catched my interest:
- The importance of graphs (well, yes, of course, is a workshop about graphs), and how now that the software aiming for graph structures is raising, we need hardware that is particularly designed for graphs: the Graphcore Intelligence Processing Unit (IPU). When he talked about it, it sounded a lot like something I used during my bachelors: the FPGAs. Basically, a computer specifically designed for parallel computing. I did a quick read online, and it seems like both are optimized for parallel computing, with the Graphcore being specially designed for (surprise surprise) graph structures, and the FPGA being more flexible for any kind of parallelized computing that you need. This post in Medium does quite a throughout analysis.
- FutureMapping: factorized computation for spatial AI. A framework that parallelizes computing between the nodes in a graph. Then, those nodes randomly communicate with each other in order to optimize computational resources. Here is a link to the paper and a link to an online tutorial.
W.1.A. A new factor-graph lens on (Clustered) Belief Propagation
by Frank Dellaert
Before getting into factor graphs, he quickly mentioned his recent work in NeRFs. See a post about it here. He also advertised a free book with jupyter notebooks with different aspects about robotics available here. Definitely worth looking into!
Brief review of factor graphs
Frank Dellaert’s work on factor graphs is very well known and available on a free book. At the begginning of the talk, he did a quick review on the theory within that book.
My quick notes:
The use of factor graphs allows Sparse matrix factorization. Then we can apply QR factorization on Factor Graphs. The Bayes tree is a powerful graphical model that enables incremental Smoothing and Mapping (iSAM). An example on iSAM is available here at section 7 and here.
Gibbs sampling via elimination
This procedure was explained with code examples available here.
Take a nonlinear factor graph, for example, one in which the measurements come from a bearing sensor. When obtaining joint Marginals of graph variables results are “wrong” because the problem is nonlinear, and the result is a Laplace approximation. We can get better results by Gibbs sampling. First pick Markov blanket. Keep sucesion of samples given the current state of the other variables (elimination). Instead of Laplace approximation, use it as Metropolis proposal.
A different take on loopy BP
Similarly, code examples available here.
Belief propagation: variation approximation. Approximate true posterior with simpler density. Pretend true posterior is multiplication of factors. Converges to true mean but covariances are overconfident. Loopy SAM (2007): Gauss-Seidel propagation. Opposite to Gibbs Sampling: eliminate separator last.
Clustered belief propagation
More code examples.
Identify clusters and for a variational approximation at the cluster level – rather than individual belief factors, have Bayes nets/trees as variational components. Basically cluster the graph. Uses all sparsity available in the system. Converges much faster because explores inherent structure of the domain.
W.2. ICRA 2023 Workshop on Unconventional spatial representations: Opportunities for robotics

I only attended one talk in this workshop. It seemed to be about using unconventional sensors for perception tasks in general, for what I could see on the posters. Unfortunately, the posters are not available online and I didn’t take photos of them.
W.2.A. Understanding and Representing the Sea environment for Autonomous Ship Navigation
by Hyun-Taek Choi
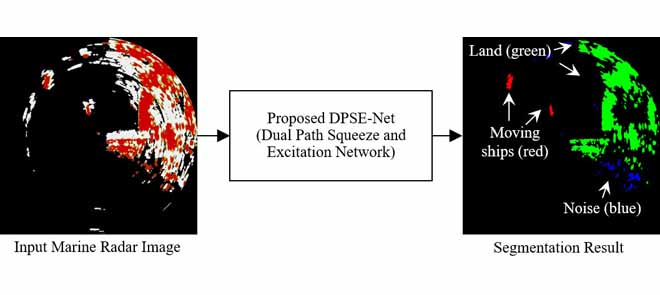
As a professor in the Korea Research Institute of Ships and Ocean Engineering, he presented quite some interesting field words in that context. I noted down this one, available as a paper here:
“Marine Object Segmentation and Tracking by Learning Marine Radar Images for Autonomous Surface Vehicles”. The title is self-explanatory. Some capabilities they claim for they network are
- Noise reduction (because radar is extremely noisy)
- Detecting Small object and fast moving objects.
W.3. Workshop on effective Representations, Abstractions, and Priors for Robot Learning (RAP4Robots)
 When I joined this workshop there was a Pannel session taking part, with professors discussing around the question: “Do better representation lead to better generalization?”. E.g., about the possibility of using an alternative to Euclidean maps and object poses, and about applying representation learning. There was no clear conclusion on the question, which I think is a good sign for this being an open research question.
When I joined this workshop there was a Pannel session taking part, with professors discussing around the question: “Do better representation lead to better generalization?”. E.g., about the possibility of using an alternative to Euclidean maps and object poses, and about applying representation learning. There was no clear conclusion on the question, which I think is a good sign for this being an open research question.
W.3.A. A trilogy of priors: the vision the design and the data
by Edward Johns
Edward introduced to us a series of very works within his field of research, which is robot manipulation. This one called my attention, since they use generative models (more concretely, DALL-E) to generate different arrangements for the objects in the image.
W.4. Pretraining for Robotics (PT4R)

W.4.A. Where are we in the search for an Artificial Visual Cortex for Embodied Intelligence?
by Franziska Meier
From the paper under the same title which can be found here
Day 3. Orals and Posters
O.1. Award Finalists
O.1.1. Graph Neural Networks for Multi-Robot Active Information Acquisition
by Mariliza Tzes
- Active information acquisition
- Team of drones – no dinamics – they have sensors. The dynamics are the hidden state.
- Planning horizon – informative path
- They try to reach scalability, computational efficiency and optimality with I-GBNet.
- Robots exchange info with neighbors, forming a communications graph. Network graph contains info about robot state – fed into I-GBNet to be updated. For each node, predict control input for robot.
- Message passing layer:
- Robot grid map.
- Message passing aggregates robots position.
- Each robot has its own estimate about hidden state that is propagated through graph.
- Bayes filter to fuse measurements.
- Obtain occupancy grid of environment.
- ResNet blocks to encode the paths within the grid representation.
- Then predict control input.
O.2. Localization I
O.2.1. Robust Visual Localization of a UAV Over a Pipe-Rack Based on the Lie Group SE(3)
by Jonathan Cacace
They fed the CAD model of the pipe rack to estimate the scale. Feature points are projected onto the CAD.
The code (MATLAB, simulated) for this work is available here
O.2.2. Homography-Based Loss Function for Camera Pose Regression
by Clémentin Boittiaux
 Image: Convergence of the proposed Homography loss. From the original repo available here.
Image: Convergence of the proposed Homography loss. From the original repo available here.
- SOA: Inertial measuruement based catenary […] underwater vehicles.
- Same metric as structure from motion
- Projected to infinity function no differentiable
- Reprojection loss doesn’t have these problems.
O.3. Deep Learning for Visual Perception
O.3.1. Object-Aware Monocular Depth Prediction with Instance Convolutions
by Enis Simsar and Evin Pinar
- InstanceConv takes segmentation mask into account.
- Aggregates features coming from same segment. They use superpixels segmentation mask as input.
- Superpixels can oversegment depending on light intensity, but they can used in “any” scence as opposed to trained methods. MaskCNN etc don’t have guarantee over occlusion boundaries. Superpixels are off-the-shelf, don’t require training.
The code is available here
O.3.2. Uncertainty guided policy for active robotic 3D reconstruction using Neural Radiance Fields
by Soomin Lee
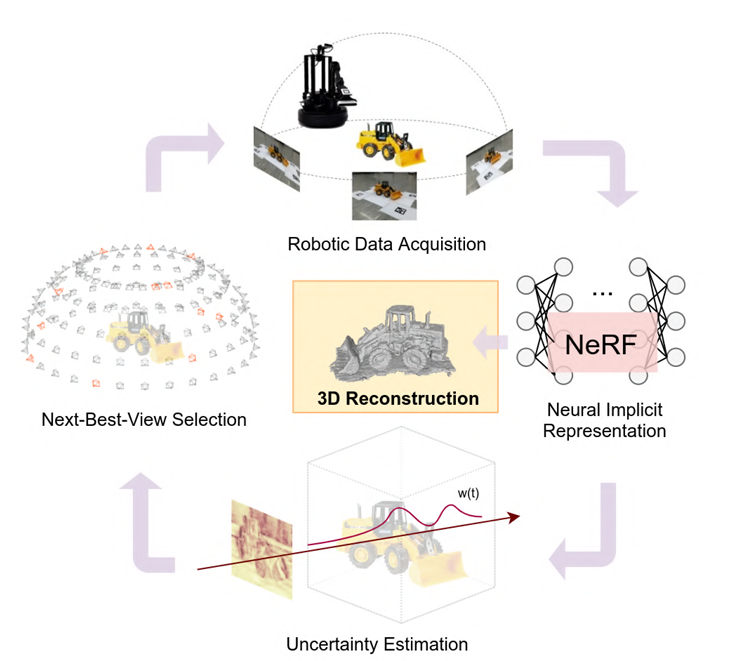
- Instead of voxels n stuff, using NERFs.
- They suggest new paradigm: Ray-based volumentric uncertainty. Uncertainty in ray space.
- Weighted combination of colors, weight distribution of colors to measure how certain – a color has to have a clear peak?
- Entropy metric – low entropy clear distribution peak
This work’s website (not code though) is here.
O.3.3 Detaching and Boosting: Dual Engine for Scale-Invariant Self-Supervised Monocular Depth Estimation
by Peizhe Jiang
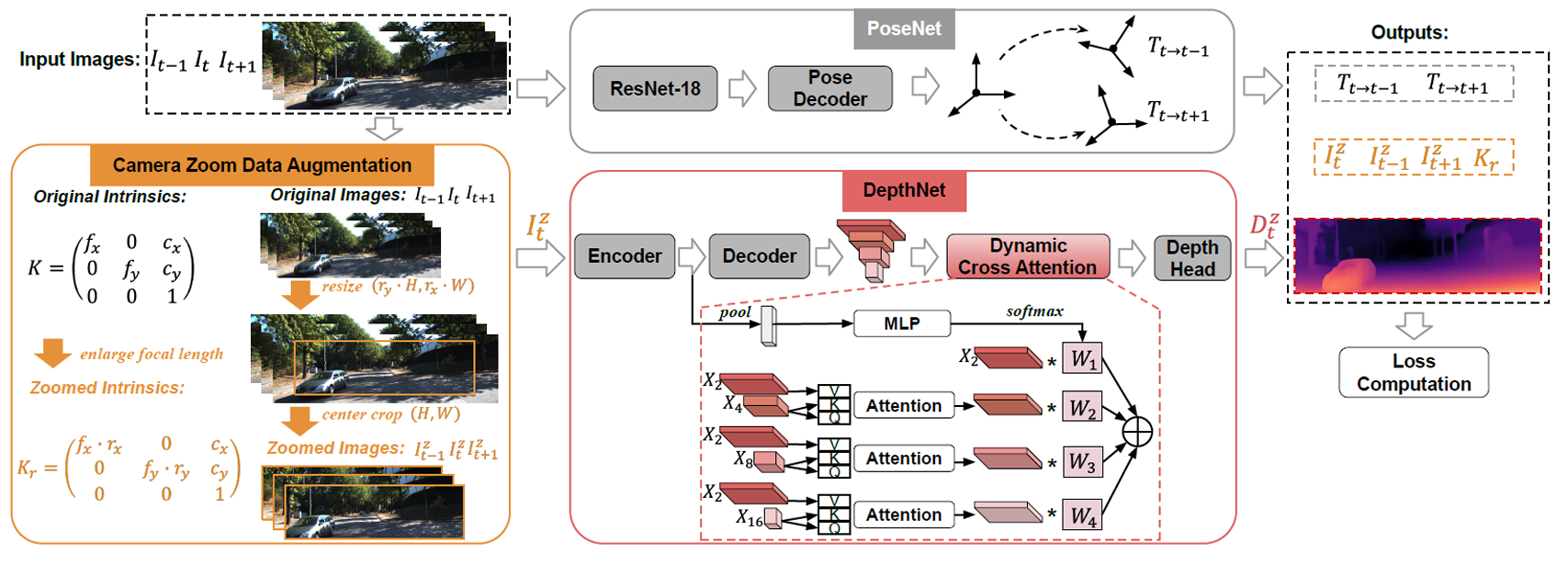
- Zooming and moving similar effects – they use zooming for data augmentation (extrinsics need to be adapted). Predict same depth for zoomed and unzoomed images (if they are the same).
- Cross attention to get relationship between objects.
This post is a work in progress…
